Flex Checkpoint工作记录
1. Flex Checkpoint关键组件
1.1 reshard_sharded_state_dict
def reshard_sharded_state_dict(
src_sharded_state_dict: ShardedStateDict,
dst_sharded_state_dict: ShardedStateDict,
process_group: Group,
coordinator_rank: int | None = 0,
offload: bool | None = False,
aoa_config: dist[str, list[str]] | None = None,
) -> None:
local_src_state_dict_shard_info = {
key: (
value.global_offset,
value.local_shape,
str(value.local_tensor.dtype).split(".")[-1],
value.global_shape,
value.is_flattened,
)
for key, value in src_sharded_state_dict.items()
}
global_src_state_dict_shard_info = []
dist.all_gather_object(
global_src_state_dict_shard_info,
local_src_state_dict_shard_info,
group=process_group,
)
src_state_dict_shard_info = {}
for rank_shard_info in global_src_state_dict_shard_info:
for key, tensor_shard_info in rank_shard_info.items():
if key not in src_state_dict_shard_info:
src_state_dict_shard_info[key] = []
src_state_dict_shard_info[key].append(tensor_shard_info)
# check validity
check_src_state_dict_validity(src_state_dict_shard_info)
local_dst_state_dict_shard_info = {
key: (
value.global_offset,
value.local_shape,
str(value.local_tensor.dtype).split(".")[-1],
value.global_shape,
value.is_flattened,
)
for key, value in dst_sharded_state_dict.items()
}
global_dst_state_dict_shard_info = []
dist.all_gather_object(
global_dst_state_dict_shard_info,
local_dst_state_dict_shard_info,
group=process_group,
)
dst_state_dict_shard_info = {}
for rank_shard_info in global_dst_state_dict_shard_info:
for key, tensor_shard_info in rank_shard_info.items():
if key not in dst_state_dict_shard_info:
dst_state_dict_shard_info[key] = []
dst_state_dict_shard_info[key].append(tensor_shard_info)
# check validity
check_dst_state_dict_validity(dst_state_dict_shard_info)
check_src_dst_state_dict_validity(
src_state_dict_shard_info, dst_state_dict_shard_info
)
# build metadata
state_dict_metadata = {
tensor_name: [
LocalTensorMetadata(
global_offset=shard_info[0],
local_shape=shard_info[1],
dtype=shard_info[2],
)
for shard_info in shard_infos
]
for tensor_name, shard_infos in src_state_dict_shard_info.items()
}
virtual_file_path = f"vfile_{dist.get_rank()}"
local_storage_metadata = {
LocalTensorIndex(
tensor_key=value.key,
global_offset=value.global_offset,
): virtual_file_path
for key, value in src_sharded_state_dict.items()
}
global_storage_metadata: list[dict[LocalTensorIndex, str]] = []
dist.all_gather_object(
global_storage_metadata,
local_storage_metadata,
group=process_group,
)
# Merge storage metadata
storage_metadata: dict[LocalTensorIndex, str] = {}
for rank_storage_metadata in global_storage_metadata:
storage_metadata.update(rank_storage_metadata)
# Prepare metadata for loading
metadata = Metadata(
state_dict_metadata=state_dict_metadata,
storage_metadata=storage_metadata,
flat_mapping=None,
)
# Extract local tensors
src_state_dict = {
key: value.local_tensor for key, value in src_sharded_state_dict.items()
}
dst_state_dict = dst_sharded_state_dict
# reshard using _load_state_dict
_load_state_dict(
target_state_dict=dst_state_dict,
source_state_dict={virtual_file_path: src_state_dict},
metadata_list=[metadata],
coordinator_rank=coordinator_rank,
process_group=process_group,
offload=offload,
)
这个函数实际是为了构建reshard过程中需要的metadata,实际的reshard操作,在load_state_dict里面。state_dict_metadata 和 storage_metadata 最终都包含了所有 rank 的分片信息,是全局的完整信息。
这里使用virtual_file_path是因为此时实际的数据已经可以取到,即每个rank上local_tensor的实际值,无需再从文件中读取,这么做是为了整个格式上的对齐。
1.1.1 全局信息的构建过程
state_dict_metadata 的构建,state_dict_metadata用来保存Tensor的全局元数据信息
# 步骤1:每个 rank 收集自己的分片信息
local_src_state_dict_shard_info = {
key: (
value.global_offset,
value.local_shape,
str(value.local_tensor.dtype).split(".")[-1],
value.global_shape,
value.is_flattened,
)
for key, value in src_sharded_state_dict.items()
}
# 步骤2:全局收集所有 rank 的信息
global_src_state_dict_shard_info = []
dist.all_gather_object(
global_src_state_dict_shard_info,
local_src_state_dict_shard_info,
group=process_group,
)
# 结果:每个 rank 都有所有 rank 的信息
global_src_state_dict_shard_info = [
# rank 0 的信息
{"linear.weight": ((0, 0), (256, 512), "float32", (1024, 512), False)},
# rank 1 的信息
{"linear.weight": ((256, 0), (256, 512), "float32", (1024, 512), False)},
# rank 2 的信息
{"linear.weight": ((512, 0), (256, 512), "float32", (1024, 512), False)},
# rank 3 的信息
{"linear.weight": ((768, 0), (256, 512), "float32", (1024, 512), False)},
]
# 步骤3:重组为按张量分组的全局信息
src_state_dict_shard_info = {
"linear.weight": [
((0, 0), (256, 512), "float32", (1024, 512), False), # rank 0
((256, 0), (256, 512), "float32", (1024, 512), False), # rank 1
((512, 0), (256, 512), "float32", (1024, 512), False), # rank 2
((768, 0), (256, 512), "float32", (1024, 512), False), # rank 3
]
}
# 步骤4:构建全局的 state_dict_metadata
state_dict_metadata = {
"linear.weight": [
LocalTensorMetadata(global_offset=(0, 0), local_shape=(256, 512), dtype="float32"), # rank 0
LocalTensorMetadata(global_offset=(256, 0), local_shape=(256, 512), dtype="float32"), # rank 1
LocalTensorMetadata(global_offset=(512, 0), local_shape=(256, 512), dtype="float32"), # rank 2
LocalTensorMetadata(global_offset=(768, 0), local_shape=(256, 512), dtype="float32"), # rank 3
]
}
storage_metadata 的构建,storage_metadata 用来保存Tensor实际数据保存的位置信息
# 步骤1:每个 rank 构建自己的存储映射
virtual_file_path = f"vfile_{dist.get_rank()}"
local_storage_metadata = {
LocalTensorIndex(
tensor_key=value.key,
global_offset=value.global_offset,
): virtual_file_path
for key, value in src_sharded_state_dict.items()
}
# rank 0 的本地映射
local_storage_metadata = {
LocalTensorIndex("linear.weight", (0, 0)): "vfile_0",
}
# 步骤2:全局收集所有 rank 的存储映射
global_storage_metadata: list[dict[LocalTensorIndex, str]] = []
dist.all_gather_object(
global_storage_metadata,
local_storage_metadata,
group=process_group,
)
# 结果:每个 rank 都有所有 rank 的存储映射
global_storage_metadata = [
# rank 0 的映射
{LocalTensorIndex("linear.weight", (0, 0)): "vfile_0"},
# rank 1 的映射
{LocalTensorIndex("linear.weight", (256, 0)): "vfile_1"},
# rank 2 的映射
{LocalTensorIndex("linear.weight", (512, 0)): "vfile_2"},
# rank 3 的映射
{LocalTensorIndex("linear.weight", (768, 0)): "vfile_3"},
]
# 步骤3:合并为全局的 storage_metadata
storage_metadata: dict[LocalTensorIndex, str] = {}
for rank_storage_metadata in global_storage_metadata:
storage_metadata.update(rank_storage_metadata)
# 最终的全局 storage_metadata
storage_metadata = {
LocalTensorIndex("linear.weight", (0, 0)): "vfile_0", # rank 0
LocalTensorIndex("linear.weight", (256, 0)): "vfile_1", # rank 1
LocalTensorIndex("linear.weight", (512, 0)): "vfile_2", # rank 2
LocalTensorIndex("linear.weight", (768, 0)): "vfile_3", # rank 3
}
1.1.2 为什么需要全局信息?
重分片需要完整的分片信息
# 重分片过程:
# 源:4 个分片 -> 目标:2 个分片
# 需要知道所有源分片的信息才能正确重分片
source_shards = [
((0, 0), (256, 512)), # rank 0
((256, 0), (256, 512)), # rank 1
((512, 0), (256, 512)), # rank 2
((768, 0), (256, 512)), # rank 3
]
# 目标分片需要从多个源分片组合数据
target_shard_0 = combine(source_shards[0], source_shards[1]) # 需要 rank 0 和 rank 1 的数据
target_shard_1 = combine(source_shards[2], source_shards[3]) # 需要 rank 2 和 rank 3 的数据
** 数据访问需要全局映射**
# _load_state_dict 需要知道:
# 1. 每个分片在哪里(storage_metadata)
# 2. 每个分片的形状和位置(state_dict_metadata)
def load_shard(tensor_name, global_offset):
# 根据全局信息找到对应的分片
index = LocalTensorIndex(tensor_name, global_offset)
file_path = storage_metadata[index] # "vfile_0"
# 从对应的数据源获取数据
if file_path in source_state_dict:
return source_state_dict[file_path][tensor_name]
** 验证需要全局视图**
# 验证分片完整性需要全局信息
def validate_completeness():
# 检查是否所有分片都存在
expected_shards = [
(0, 0), (256, 0), (512, 0), (768, 0)
]
for offset in expected_shards:
index = LocalTensorIndex("linear.weight", offset)
if index not in storage_metadata:
raise ValueError(f"Missing shard at {offset}")
1.2 utils相关工具组件总结
1. 索引转换工具
ravel_index(indices, shape)
def ravel_index(indices, shape):
idx = 0
for i, dim in zip(indices, shape):
idx = idx * dim + i
return idx
作用:将多维索引转换为线性索引(行优先顺序)
详细解释:
# 例子:shape = (2, 3, 4)
# 多维索引 (1, 2, 3) 转换为线性索引
# 计算过程:
# i=0: idx = 0 * 2 + 1 = 1
# i=1: idx = 1 * 3 + 2 = 5
# i=2: idx = 5 * 4 + 3 = 23
# 结果:线性索引 = 23
# 验证:在2×3×4的张量中,位置(1,2,3)的线性索引确实是23
应用场景:
- 将多维张量的位置转换为内存中的线性地址
- 在分片计算中定位元素在全局张量中的位置
unravel_index(idx, shape)
def unravel_index(idx, shape):
indices = []
for dim in reversed(shape):
indices.append(idx % dim)
idx //= dim
return tuple(reversed(indices))
作用:将线性索引转换为多维索引
详细解释:
# 例子:shape = (2, 3, 4), idx = 23
# 线性索引 23 转换为多维索引
# 计算过程(从右到左):
# dim=4: indices.append(23 % 4 = 3), idx = 23 // 4 = 5
# dim=3: indices.append(5 % 3 = 2), idx = 5 // 3 = 1
# dim=2: indices.append(1 % 2 = 1), idx = 1 // 2 = 0
# 结果:多维索引 = (1, 2, 3)
应用场景:
- 从内存地址恢复多维张量的位置
- 在分片重建时确定元素在全局张量中的坐标
2. 切片计算工具
minimal_nd_slice(shape, flat_start, flat_end)
def minimal_nd_slice(shape, flat_start, flat_end):
start_idx = unravel_index(flat_start, shape)
end_idx = unravel_index(flat_end - 1, shape)
min_slices = []
for axis in range(len(shape)):
if axis == 0:
s = start_idx[axis]
e = end_idx[axis] + 1
else:
if start_idx[axis - 1] == end_idx[axis - 1]:
s = min(start_idx[axis], end_idx[axis])
e = max(start_idx[axis], end_idx[axis]) + 1
else:
s = 0
e = shape[axis]
min_slices.append((s, e))
return min_slices, start_idx, end_idx
作用:计算包含给定扁平化范围的最小N维切片
详细解释:
# 例子:shape = (4, 3), flat_start = 5, flat_end = 8
# 扁平化范围 [5, 8) 转换为最小切片
# 计算过程:
# start_idx = unravel_index(5, (4, 3)) = (1, 2)
# end_idx = unravel_index(7, (4, 3)) = (2, 1)
# 对于axis=0:
# s = 1, e = 2 + 1 = 3
# 对于axis=1:
# start_idx[0] = 1, end_idx[0] = 2, 不相等
# 所以 s = 0, e = 3
# 结果:min_slices = [(1, 3), (0, 3)]
# 这表示需要切片 [1:3, 0:3]
应用场景:
- 将扁平化的索引范围转换为最优的多维切片
- 减少数据传输量,提高效率
flat_range_in_min_slice(shape, min_slices, flat_start, flat_end)
def flat_range_in_min_slice(shape, min_slices, flat_start, flat_end):
min_starts = tuple(s[0] for s in min_slices)
min_flat_start = ravel_index(min_starts, shape)
return flat_start - min_flat_start, flat_end - min_flat_start
作用:计算在最小切片中的相对扁平化范围
详细解释:
# 例子:shape = (4, 3), min_slices = [(1, 3), (0, 3)]
# flat_start = 5, flat_end = 8
# 计算过程:
# min_starts = (1, 0)
# min_flat_start = ravel_index((1, 0), (4, 3)) = 3
# 相对范围 = (5 - 3, 8 - 3) = (2, 5)
# 这表示在最小切片内的相对位置
应用场景:
- 计算在切片内的相对偏移
- 用于精确的数据提取和复制
3. 状态字典检查工具
is_sharded_state_dict(o)
def is_sharded_state_dict(o):
if not isinstance(o, dict):
return False
values = list(o.values())
has_sharded_weight = any(isinstance(v, ShardedWeight) for v in values)
if has_sharded_weight:
if not all(isinstance(v, ShardedWeight) for v in values):
raise TypeError(
"All values must be ShardedWeight if any value is ShardedWeight."
)
return True
else:
return False
作用:检查字典是否为分片状态字典
详细解释:
# 检查规则:
# 1. 必须是字典类型
# 2. 如果任何值是ShardedWeight,则所有值都必须是ShardedWeight
# 3. 不允许混合类型
# 例子:
valid_dict = {
"weight": ShardedWeight(...),
"bias": ShardedWeight(...)
} # 返回 True
invalid_dict = {
"weight": ShardedWeight(...),
"bias": paddle.Tensor(...)
} # 抛出TypeError
应用场景:
- 验证检查点格式的正确性
- 确保状态字典的一致性
4. 重叠区域计算工具
get_overlap_region(desc_offset, desc_shape, shard_offset, shard_shape)
def get_overlap_region(desc_offset, desc_shape, shard_offset, shard_shape):
ndim = len(desc_offset)
overlap_offset = []
overlap_shape = []
desc_starts = []
shard_starts = []
for i in range(ndim):
desc_lo = desc_offset[i]
desc_hi = desc_offset[i] + desc_shape[i]
shard_lo = shard_offset[i]
shard_hi = shard_offset[i] + shard_shape[i]
# overlap
lo = max(desc_lo, shard_lo)
hi = min(desc_hi, shard_hi)
if lo >= hi:
return False, None, None, None, None
overlap_offset.append(lo)
overlap_shape.append(hi - lo)
desc_starts.append(lo - desc_lo)
shard_starts.append(lo - shard_lo)
return True, overlap_offset, overlap_shape, desc_starts, shard_starts
作用:计算两个分片之间的重叠区域
详细解释:
# 例子:2D张量
# desc: offset=(0,0), shape=(4,4)
# shard: offset=(2,2), shape=(4,4)
# 计算过程:
# 维度0:
# desc_lo=0, desc_hi=4, shard_lo=2, shard_hi=6
# lo = max(0,2) = 2, hi = min(4,6) = 4
# overlap_offset[0] = 2, overlap_shape[0] = 2
# desc_starts[0] = 2-0 = 2, shard_starts[0] = 2-2 = 0
# 维度1:
# desc_lo=0, desc_hi=4, shard_lo=2, shard_hi=6
# lo = max(0,2) = 2, hi = min(4,6) = 4
# overlap_offset[1] = 2, overlap_shape[1] = 2
# desc_starts[1] = 2-0 = 2, shard_starts[1] = 2-2 = 0
# 结果:
# 重叠区域:offset=(2,2), shape=(2,2)
# 在desc中的起始:(2,2)
# 在shard中��的起始:(0,0)
应用场景:
- 计算不同分片策略间的数据重叠
- 为数据复制提供精确的范围信息
5. 分片数据复制工具
assign_sharded_slice(src_desc, src_shard, dst_desc, dst_shard)
def assign_sharded_slice(src_desc, src_shard, dst_desc, dst_shard):
# 1. 计算源分片的重叠区域
src_has, _, overlap_shape, src_desc_starts, src_shard_starts = (
get_overlap_region(
src_desc.global_offset,
src_desc.local_shape,
src_shard.global_offset,
src_shard.local_shape,
)
)
# 2. 计算目标分片的重叠区域
dst_has, _, overlap_shape2, dst_desc_starts, dst_shard_starts = (
get_overlap_region(
dst_desc.global_offset,
dst_desc.local_shape,
dst_shard.global_offset,
dst_shard.local_shape,
)
)
# 3. 验证重叠区域一致性
assert src_has or dst_has, "no overlap!"
assert overlap_shape == overlap_shape2, "overlap shape mismatch!"
# 4. 执行数据复制
axes = list(range(len(overlap_shape)))
src_tensor_slice = paddle.slice(
src_shard.local_tensor,
axes=axes,
starts=src_shard_starts,
ends=[s + o for s, o in zip(src_shard_starts, overlap_shape)],
)
dst_tensor_slice = paddle.slice(
dst_shard.local_tensor,
axes=axes,
starts=dst_shard_starts,
ends=[s + o for s, o in zip(dst_shard_starts, overlap_shape)],
)
paddle.assign(src_tensor_slice, dst_tensor_slice)
作用:在不同分片间复制重叠数据
详细解释:
# 完整流程:
# 1. 计算源分片与描述符的重叠区域
# 2. 计算目标分片与描述符的重叠区域
# 3. 验证两个重叠区域的一致性
# 4. 从源分片提取重叠部分
# 5. 复制到目标分片
# 例子:从tp2转换到tp4
# src_desc: 描述tp2时的分片布局
# src_shard: tp2时的实际数据
# dst_desc: 描述tp4时的分片布局
# dst_shard: tp4时的目标数据
# 函数会:
# 1. 找到tp2和tp4分片的重叠部分
# 2. 将tp2的重叠数据复制到tp4的对应位置
应用场景:
- 分片策略转换时的数据重分布
- 检查点加载时的数据恢复
6. 信息合并工具
merge_shard_info_list(list_of_dicts)
def merge_shard_info_list(list_of_dicts):
merged = defaultdict(list)
for info in list_of_dicts:
for k, v in info.items():
merged[k].extend(v)
return dict(merged)
作用:合并多个分片信息字典
详细解释:
# 例子:
list_of_dicts = [
{"param1": [info1, info2]},
{"param1": [info3], "param2": [info4]},
{"param2": [info5, info6]}
]
# 合并结果:
merged = {
"param1": [info1, info2, info3],
"param2": [info4, info5, info6]
}
应用场景:
- 收集所有rank的分片信息
- 构建全局的分片视图
7. 描述符构建工具
build_shard_desc(val)
def build_shard_desc(val):
return ShardedWeightDesc(
key=val.key,
local_shape=tuple(val.local_shape),
global_shape=tuple(val.global_shape),
global_offset=tuple(val.global_offset),
)
作用:从ShardedWeight构建ShardedWeightDesc
详细解释:
# 转换过程:
# 输入:ShardedWeight对象(包含实际数据)
# 输出:ShardedWeightDesc对象(仅包含元数据)
# 例子:
sharded_weight = ShardedWeight(
key="linear.weight",
local_tensor=paddle.Tensor(...), # 实际数据
local_shape=(1024, 512),
global_shape=(1024, 2048),
global_offset=(0, 0)
)
# 转换为:
shard_desc = ShardedWeightDesc(
key="linear.weight",
local_shape=(1024, 512),
global_shape=(1024, 2048),
global_offset=(0, 0)
)
应用场景:
- 提取分片权重的元数据信息
- 用于分片信息的传输和存储
1.3 sharded_tensor的关键组件
class ShardedTensor:
"""
Represents a local shard of a distributed tensor parameter.
Args:
key (str): The name of the parameter.
local_tensor (Tensor): The local shard of the parameter.
local_shape (Tuple[int, ...]): The shape of the local shard.
global_shape (Tuple[int, ...]): The global logical shape of the parameter.
global_offset (Tuple[int, ...]): The offset of the local shard in the global parameter.
is_flattened (bool, optional): Whether the parameter has been flattened (used in sharding_v2 scenarios). Default is False.
flattened_range (slice, optional): If the parameter is flattened, this indicates the index range of the actual local shard within the local_tensor.
"""
def __init__(
self,
key: str,
local_tensor: Tensor,
local_shape: tuple[int, ...],
global_shape: tuple[int, ...],
global_offset: tuple[int, ...],
is_flattened: bool = False,
flattened_range: slice | None = None,
) -> None:
self.key = key
self.local_tensor = local_tensor
self.local_shape = local_shape
self.global_shape = global_shape
self.global_offset = global_offset
self.is_flattened = is_flattened
self.flattened_range = flattened_range
def __str__(self) -> str:
"""Returns a formatted string representation of the sharded tensor."""
return (
f"ShardedTensor(\n"
f" key={self.key},\n"
f" local_tensor={type(self.local_tensor).__name__}(shape={self.local_tensor.shape}),\n"
f" local_shape={self.local_shape},\n"
f" global_shape={self.global_shape},\n"
f" global_offset={self.global_offset},\n"
f" flattened_range={self.flattened_range}\n"
f")"
)
def shard_weight(
key: str,
weight: Tensor,
axis: int,
group: Group,
) -> ShardedTensor:
"""Creates a ShardedTensor by splitting the input tensor along a specified axis.
Args:
key: Unique identifier for the tensor.
weight: The input tensor to be sharded.
axis: The axis along which to shard the tensor.
group: The process group used for distributed communication.
Returns:
A ShardedTensor representing the local portion of the global tensor.
"""
if axis < 0 or axis >= len(weight.shape):
raise ValueError(
f"Shard axis {axis} is invalid for tensor with shape {weight.shape}"
)
# Get hybrid communication group and rank information
hcg = fleet.get_hybrid_communicate_group()
current_rank = group.rank
world_size = group.nranks
# Calculate shapes and offsets
local_shape = weight.shape
global_shape = deepcopy(local_shape)
global_shape[axis] = local_shape[axis] * world_size
global_shape = tuple(global_shape)
local_shape = tuple(local_shape)
global_offset = [0] * len(global_shape)
if world_size > 1:
global_offset[axis] = current_rank * local_shape[axis]
global_offset = tuple(global_offset)
return ShardedTensor(
key=key,
local_tensor=weight,
local_shape=local_shape,
global_shape=global_shape,
global_offset=global_offset,
)
def build_sharded_state_dict(
state_dict: dict[str, Tensor],
shard_rules: dict[str, int] | None = None,
prefix: str = "",
) -> dict[str, ShardedTensor]:
"""Converts a regular state dict to a sharded state dict based on sharding rules.
Args:
state_dict: The original state dictionary containing tensors
shard_rules: Dictionary mapping tensor names to their sharding axes.
If None, treated as empty dict (no tensor parallelism).
prefix: Optional prefix to prepend to all tensor keys
Returns:
Dictionary with the same keys as input but values converted to ShardedTensor
or regular Tensor based on sharding rules.
Note:
Tensors not in shard_rules will be wrapped as non-sharded ShardedTensors.
"""
shard_rules = shard_rules or {}
sharded_state_dict = {}
for key, tensor in state_dict.items():
full_key = f"{prefix}{key}" if prefix else key
if key in shard_rules:
# Apply tensor parallelism sharding
sharded_state_dict[full_key] = (
make_tp_sharded_tensor_for_checkpoint(
key=full_key,
tensor=tensor,
tensor_parallel_axis=shard_rules[key],
)
)
else:
# Create regular sharded tensor (non-tensor-parallel)
sharded_state_dict[full_key] = make_replicated_sharded_tensor(
key=full_key,
tensor=tensor,
)
return sharded_state_dict
主要是ShardedTensor类和build_sharded_state_dict、shard_weight两个接口,ShardedTensor主要是作为后续shard_state_dict中的基础单元,即字典格式(key: ShardedTensor),原来版本是普通的Tensor,而现在的ShardedTensor携带了Tensor切分的信息,主要是local_shape、global_shape、global_offset则可以据此对local_tensor进行全局tensor的重建,再对齐进行reshard。build_sharded_state_dict是在普通的state_dict的基础上,对于需要做分布式处理的(即shard)tensor进行切分标记,将tensor转化为ShardedTensor,make_tp_sharded_tensor_for_checkpoint其实就是做mp参数并行,里面调用的就是shard_weight接口,返回一个ShardedTensor;对于不需要切分的,也要用make_replicated_sharded_tensor处理,将其转化为统一的ShardedTensor类,这部分处理无需调用shard_weight,直接返回ShardedTensor,local_shape=global_shape,因为每个rank上保存的这部分数据都一样。而shard_weight,传入进来的tensor,对应切分的那个维度的数据,每个rank都不一样(对于shard组来说),因此将每个rank上该tensor的对应维度的shape加起来,即可得到global_shape,从而构造出具有分布式信息的Tensor。
1.4 load_state_dict的关键组件
1.4.1 get_rank_to_files(与原来的一致)
ef get_rank_to_files(
metadata_list,
local_data_files,
state_dict,
process_group,
use_dist,
mw_name_compatibility=True,
):
"""
Get the mapping of rank to its accessible files.
"""
# The necessary files to be read
tensor_key_list = []
necessary_files = []
mw_name_compatibility_mapping = {}
for metadata in metadata_list:
for local_tensor_index, file_name in metadata.storage_metadata.items():
assert (
local_tensor_index not in tensor_key_list
), f"Duplicate tensor_key:{local_tensor_index} found. Check whether the metadata."
tensor_key_list.append(local_tensor_index.tensor_key)
if local_tensor_index.tensor_key in state_dict:
necessary_files.append(file_name)
all_necessary_files = []
if use_dist:
paddle.distributed.all_gather_object(
all_necessary_files, necessary_files, process_group
)
else:
all_necessary_files.append(necessary_files)
global_necessary_files = [
file for files in all_necessary_files for file in files
]
global_necessary_files_set = set(global_necessary_files)
if len(global_necessary_files_set) <= 0:
logger.warning(
"No necessary data files found in the checkpoint directory. Please check the metadata."
)
missing_keys = set(state_dict.keys())
return {}, missing_keys, mw_name_compatibility_mapping
# allgather all accessible files
global_data_files = []
if use_dist:
paddle.distributed.all_gather_object(
global_data_files, local_data_files, process_group
)
else:
global_data_files.append(local_data_files)
tmp = []
for files in global_data_files:
tmp += files
global_data_files_set = set(tmp)
logger.debug(
f"necessary_data_files_set:{global_necessary_files_set}, global_data_files_set:{global_data_files_set}"
)
# check necessary files in global_data_files
assert (
global_data_files_set & global_necessary_files_set
== global_necessary_files_set
), f"The checkpoint files are not complete. Please check the checkpoint directory. global_data_files_set:{global_data_files_set}, necessary_data_files_set:{global_necessary_files_set}"
missing_keys = set(state_dict.keys()) - set(tensor_key_list)
if len(missing_keys) > 0:
if mw_name_compatibility:
mw_name_compatibility_mapping = _modify_mw_name_for_compatibility(
state_dict, missing_keys, tensor_key_list
)
if len(missing_keys) > 0:
logger.warning(
f"Missing keys:{missing_keys}, check whether the checkpoint is complete."
)
else:
logger.warning(
f"Missing keys:{missing_keys}, check whether the checkpoint is complete."
)
rank_to_files = {}
for rank, need_files in enumerate(all_necessary_files):
seen = set()
unique_need_files = [
f for f in need_files if not (f in seen or seen.add(f))
]
rank_to_files[rank] = unique_need_files
logger.debug(f"mapping rank_to_files:{rank_to_files}")
return rank_to_files, missing_keys, mw_name_compatibility_mapping
根据保存的storage_metadata,遍历当前rank上的state_dict,根据local_tensor_index.tensor_key是否在state_dict中,来确定是否需要当前local_tensor_index对应的文件,如果需要就添加到necessary_files中,all_necessary_files保存的是所有rank的necessary_files,如下:
all_necessary_files = [
["0_0.distcp", "1_0.distcp"], # rank 0 需要的文件
["2_0.distcp", "3_0.distcp"], # rank 1 需要的文件
["4_0.distcp", "5_0.distcp"], # rank 2 需要的文件
["6_0.distcp", "7_0.distcp"], # rank 3 需要的文件
]
即key就是rank id,value就是该rank需要的文件列表,seen是用来去重的。
1.5 paddlenlp适配
结论:因为只有 LlamaLMHead 的分片保存规则在本文件里需要“特殊约定”,其它层要么已经在各自实现里内建了 sharded_state_dict,要么可以用默认递归收集;而 LM Head 需要显式告诉检查点系统“按哪一维切”。
为什么只有 LlamaLMHead 和 PipelinePretrainedModel 需要适配?
1.LlamaLMHead
-
LM Head 的权重轴不固定:
LlamaLMHead支持transpose_y和词表并行(vocab parallel)。这会改变权重逻辑形状与“被切分的维度”:-
当
transpose_y=True且tie_word_embeddings时,weight形状是[vocab_size, hidden_size],切分轴应为axis=0。 -
否则通常是
[hidden_size, vocab_size],切分轴应为axis=1。 -
代码中专门计算了
axis = 0 if self.transpose_y else 1,然后:# L2000-L2006
state_dict = self.state_dict(structured_name_prefix="")
return build_sharded_state_dict(state_dict, {"weight": axis}, structured_name_prefix)这一步确保统一检查点能正确记录“词表维度”的切分方式,便于跨并行策略重构权重。
-
-
其它模块已有分片实现或可用默认机制:
- 注意力/MLP里用的
ColumnParallelLinear、RowParallelLinear(以及对应的 Sequence Parallel 版本)在它们各自的实现里已经处理了分片参数保存;模型其他权重(如LlamaRMSNorm.weight)不涉及并行切分轴的歧义,默认递归即可。 - 词嵌入
VocabParallelEmbedding也在并行库里有自己的分布式属性与导出路径。
- 注意力/MLP里用的
-
LM Head 还涉及权重共享与并行输出:
tie_word_embeddings时和Embedding共享权重,且is_distributed/split_axis被设置用于张量并行。- 因此 LM Head 成为“需要显式声明切分轴”的最特殊一层,避免统一检查点在重构/重分片(如从 TP2 切换到 TP4)时出错。
2.PipelinePretrainedModel
结论:因为只有 LlamaLMHead 的分片保存规则在本文件里需要“特殊约定”,其��它层要么已经在各自实现里内建了 sharded_state_dict,要么可以用默认递归收集;而 LM Head 需要显式告诉检查点系统“按哪一维切”。
-
LM Head 的权重轴不固定:
LlamaLMHead支持transpose_y和词表并行(vocab parallel)。这会改变权重逻辑形状与“被切分的维度”:-
当
transpose_y=True且tie_word_embeddings时,weight形状是[vocab_size, hidden_size],切分轴应为axis=0。 -
否则通常是
[hidden_size, vocab_size],切分轴应为axis=1。 -
代码中专门计算了
axis = 0 if self.transpose_y else 1,然后:# L2000-L2006
state_dict = self.state_dict(structured_name_prefix="")
return build_sharded_state_dict(state_dict, {"weight": axis}, structured_name_prefix)这一步确保统一检查点能正确记录“词表维度”的切分方式,便于跨并行策略重构权重。
-
-
其它模块已有分片实现或可用默认机制:
- 注意力/MLP里用的
ColumnParallelLinear、RowParallelLinear(以及对应的 Sequence Parallel 版本)在它们各自的实现里已经处理了分片参数保存;模型其他权重(如LlamaRMSNorm.weight)不涉及并行切分轴的歧义,默认递归即可。 - 词嵌入
VocabParallelEmbedding也在并行库里有自己的分布式属性与导出路径。
- 注意力/MLP里用的
-
LM Head 还涉及权重共享与并行输出:
tie_word_embeddings时和Embedding共享权重,且is_distributed/split_axis被设置用于张量并行。- 因此 LM Head 成为“需要显式声明切分轴”的最特殊一层,避免统一检查点在重构/重分片(如从 TP2 切换到 TP4)时��出错。
2.对相关的分布式API添加shard_state_dict处理
2.1 VocabParallelEmbedding
2.1.1 接收的输入
文本输入
用户输入: "Hello world, how are you?"
分词(Tokenization)
分词结果: ["Hello", "world", ",", "how", "are", "you", "?"]
词汇表映射(Vocabulary Mapping)
词汇表: {"<PAD>": 0, "<UNK>": 1, "<BOS>": 2, "<EOS>": 3,
"Hello": 4, "world": 5, ",": 6, "how": 7, "are": 8, "you": 9, "?": 10, ...}
映射结果: [4, 5, 6, 7, 8, 9, 10]
输入到模型为词汇ID序列
模型接收的输入: x = [4, 5, 6, 7, 8, 9, 10] (词汇ID序列)
因此,VocabParallelEmbedding接收到的输入x是[batch_size,seqlenth],即多组词汇ID序列。
2.1.2 处理输入
假设vocab_size=50000,embedding_dim=1024,即有50000个词,映射成向量用1024个特征表示,每个词对应一个1024长度的特征向量:
每个词汇ID对应矩阵中的一行:
word_id=0 -> W[0, :] = [0.1, 0.2, 0.3, ..., 0.1024]
word_id=1 -> W[1, :] = [0.5, 0.1, 0.8, ..., 0.2048]
word_id=2 -> W[2, :] = [0.3, 0.7, 0.2, ..., 0.3072]
...
word_id=499999 -> W[499999, :] = [0.9, 0.4, 0.6, ..., 0.1024]
输入为:
# 输入: x = [batch_size, seq_len] (词汇ID)
# 例如: x = [[100, 250000, 500000, 750000],
# [150, 250100, 500100, 750100]]
Vocab分割后:
GPU0: W[0:250000, :] (250000行,1024列)
GPU1: W[250000:500000, :] (250000行,1024列)
GPU2: W[500000:750000, :] (250000行,1024列)
GPU3: W[750000:1000000, :] (250000行,1024列)
并行化后的查找过程:
对于输入词汇ID,每个GPU的处理:
GPU0 (负责词汇0-249999):
- 输入ID=100: 查找 W[100, :] = [0.1, 0.2, ..., 0.1024]
- 输入ID=150: 查找 W[150, :] = [0.3, 0.4, ..., 0.1024]
- 输入ID=250000: 不在范围内,返回零向量或特殊处理
- 输入ID=500000: 不在范围内,返回零向量或特殊处理
GPU1 (负责词汇250000-499999):
- 输入ID=100: 不在范围内,返回零向量
- 输入ID=250000: 查找 W[250000, :] = [0.5, 0.6, ..., 0.1024]
- 输入ID=250100: 查找 W[250100, :] = [0.7, 0.8, ..., 0.1024]
- 输入ID=500000: 不在范围内,返回零向量
GPU2 (负责词汇500000-749999):
- 输入ID=500000: 查找 W[500000, :] = [0.9, 0.1, ..., 0.1024]
- 输入ID=500100: 查找 W[500100, :] = [0.2, 0.3, ..., 0.1024]
GPU3 (负责词汇750000-999999):
- 输入ID=750000: 查找 W[750000, :] = [0.4, 0.5, ..., 0.1024]
- 输入ID=750100: 查找 W[750100, :] = [0.6, 0.7, ..., 0.1024]
最终将每张卡的结果做allreduce合并,则得到最终结果,输出为:[batch_size, seq_len, embedding_dim]。
一开始该层权重是随机初始化的,即,每个词虽然�都用向量表示,但此时是无意义的,经过训练后,相近的词embedding的数据会逐渐相似,从而在推理时,正确找到每个词的embedding。
2.2 ColumnParallelLayer与RowParallelLayer同时使用的关系
2.2.1 ColumnParallelLayer
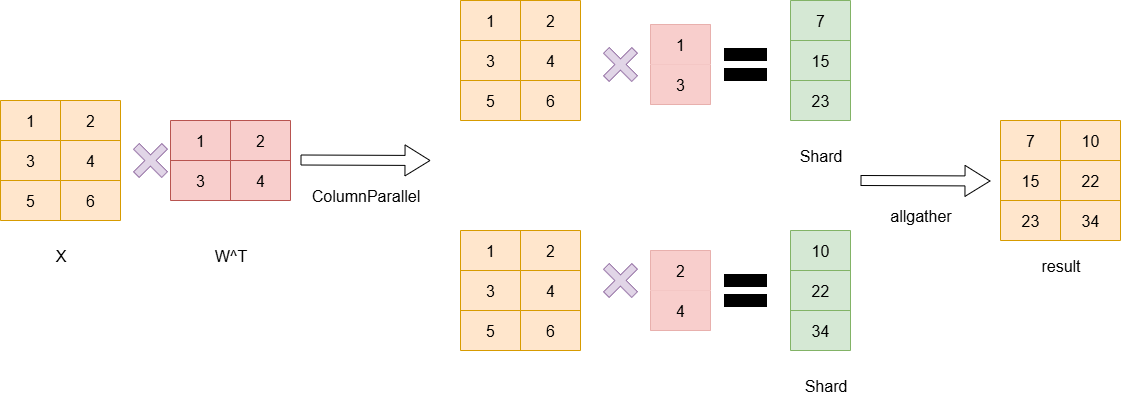
2.2.2 RowParallelLayer
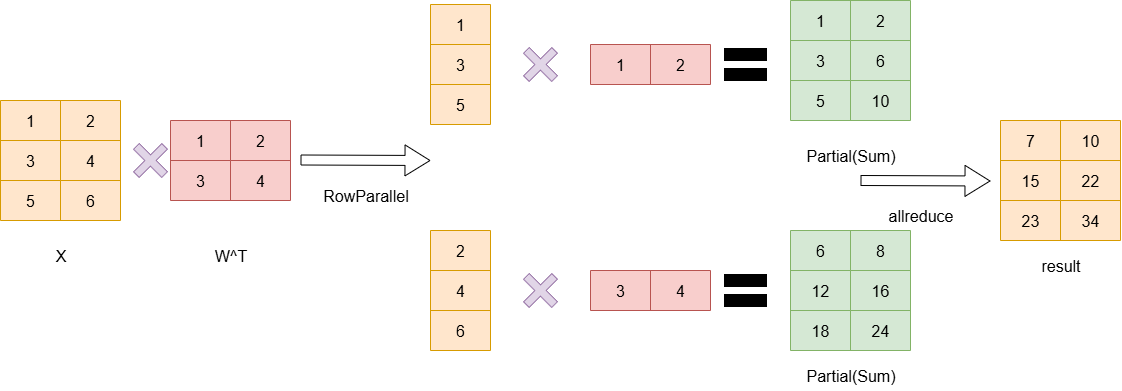
可以看到,RowParallelLayer在计算的过程中,需要把输入拆分成两列分别在两张卡上做计算,最终两张卡都得到Parital状态的数据,而如果上一层是ColumnParallel则其计算的结果刚好分配到两个设备上(即结果被按列切分),而此结果正是RowParallelLayer需要的输入,那么就无需做通信,直接继续计算最后再做allreduce即可。
2.2.3 ColumnParallelLayer与RowParallelLayer的w和bias的切分

注意,在做y=x*W^T+b的计算时,首先乘积得到的数据是[batchsize,output_size],每一行表示一个数据,而bias是分别和每一行相加,因此bias是一个一维的向量,因此,当W按列切分时,bias需要按行切分,从而保持正确的计算关系。
当添加了bias的时候,做RowParallelLayer和ColumnParallelLayer情况如下:
RowParallelLayer:
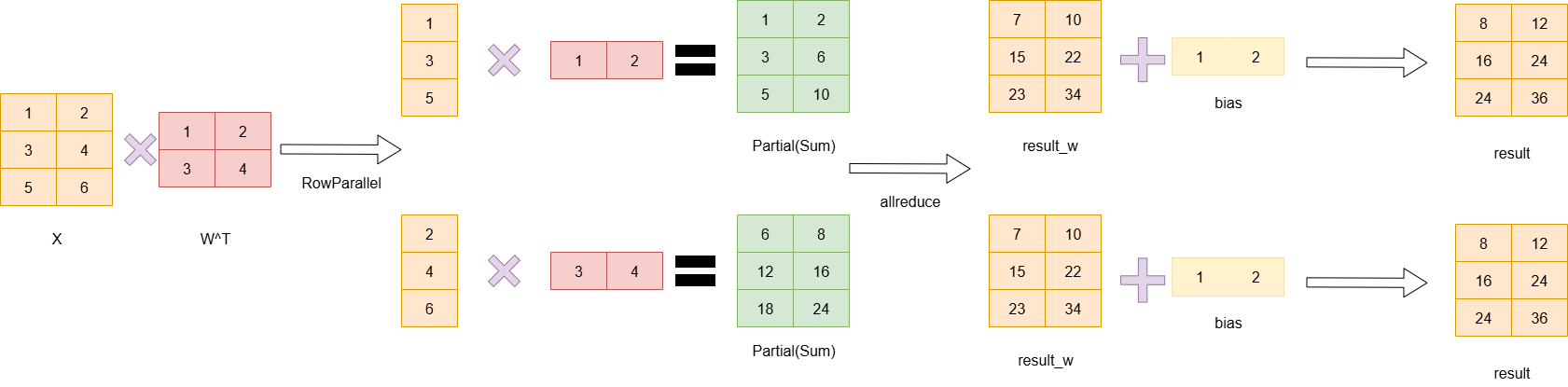
RowParallelLayer只切w,不切bias
ColumnParallelLayer:
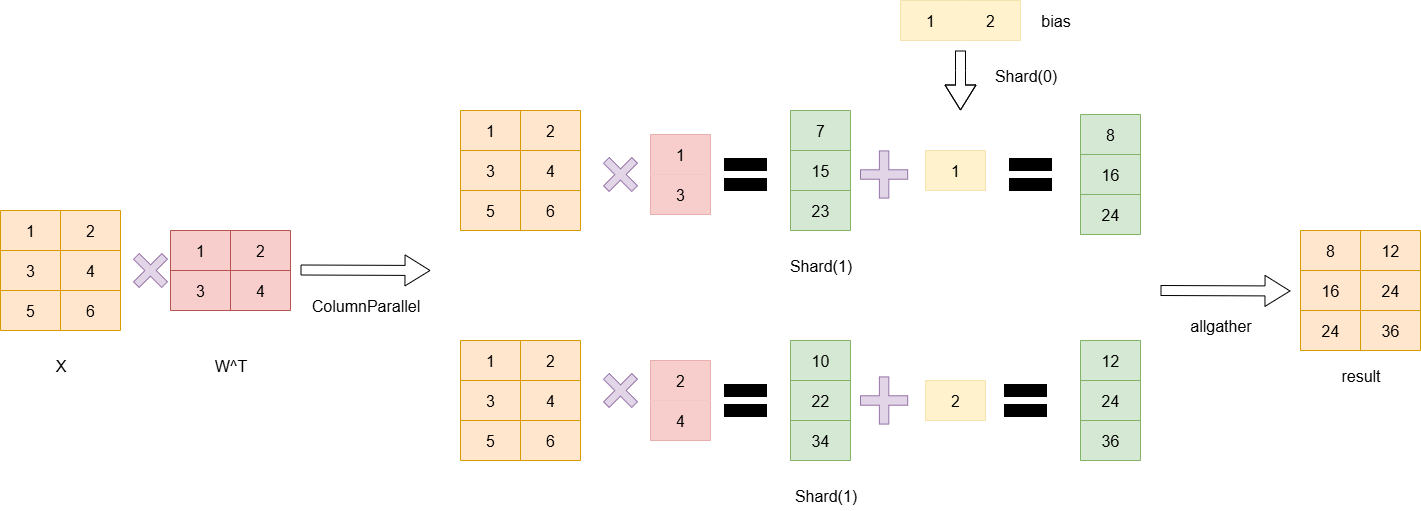
ColumnParallelLayer切w的axis=1,切bias的axis=0
2.3 DygraphShardingOptimizerV2
核心目标
sharded_state_dict 是为了解决不同并行策略间状态转换的问题,以及V2情境下,optimizer被展开铺平的问题:
- 例如从 tp2 切换到 tp4:需要重新划分参数
- 保持数据完整性:确保参数和优化器状态正确转换
- 支持断点续训:在不同并行配置间无缝切换
实现方法总结
1. 分片信息收集阶段
# 第一步:收集当前分片策略的信息
for comm_group, buffers in comm_group_buffers.items():
for buffer in buffers:
for param_name, grad_view in buffer._sharding_param_grad_view.items():
# 记录每个参数在当前rank的分片范围
param_slice_info[param_name] = (
grad_view._param_begin, # 分片起始位置
grad_view._param_end, # 分片结束位置
)
# 记录参数的完整形状信息
param_shape_info[param_name] = (
grad_view._param.shape, # 原始形状
grad_view._param.numel().item(), # 元素总数
grad_view._index, # 分片索引
grad_view._padded_size, # 填充大小
)
目的:记录当前分片策略下每个参数如何被分配到各个rank。
2. 全局信息同步阶段
# 第二步:收集所有rank的分片信息
for comm_group, buffers in comm_group_buffers.items():
# 从当前rank收集信息
param_slice_info["sharding_rank"] = comm_group.rank
# 通过all_gather收集所有rank的信息
gathered_info = []
paddle.distributed.all_gather_object(
gathered_info, param_slice_info, group=comm_group
)
all_rank_slice_info.extend(gathered_info)
目的:让每个rank都知道完整的分片分布情况,为后续重建做准备。
3. 部分分片张量识别阶段
# 第三步:识别哪些张量是部分分片的
for param_key, tensor in optim_state_dict.items():
base_name, _ = _generate_base_static_name(param_key)
if int(tensor.numel()) > 1: # 非标量张量
begin, end = merged_slice_info[base_name]
shape_info = merged_shape_info[base_name]
# 判断是否为部分分片:分片大小 < 原始大小
if shape_info and end > begin and end - begin < shape_info[1]:
partial_tensor_names.append(base_name)
目的:区分完全分片和部分分片的张量,它们需要不同的处理策略。
4. 偏移映射计算阶段
# 第四步:计算每个rank在完整张量中的偏移位置
for tensor_name in partial_tensor_names:
offset_mapping[tensor_name] = [0] * world_size
# 记录每个rank的分片大小
for info in all_rank_slice_info:
if tensor_name in info:
begin, end = info[tensor_name]
if end > begin:
offset_mapping[tensor_name][info["sharding_rank"]] = end - begin
# 转换为累积偏移
running_total = 0
for rank in range(world_size):
current_size = offset_mapping[tensor_name][rank]
offset_mapping[tensor_name][rank] = running_total
running_total += current_size
目的:为每个rank计算其在完整张量中的起始位置,用于重建完整张量。
5. 状态字典构建阶段
# 第五步:构建分片状态字典
for param_key, tensor in optim_state_dict.items():
base_name, optim_state_type = _generate_base_static_name(param_key)
struct_name = static_to_struct[base_name]
sharded_param = model_sharded_state_dict[struct_name]
unified_name = f"{struct_name}.{optim_state_type}"
# 处理三种不同类型的张量
if int(tensor.numel()) == 1:
# 标量参数:直接保存
sharded_weight = ShardedWeight(...)
elif base_name in partial_tensor_names:
# 部分分片张量:记录在完整张量中的位置
flattened_offset = offset_mapping[base_name][sharding_rank]
sharded_weight = ShardedWeight(
flattened_range=slice(flattened_offset, flattened_offset + int(tensor.numel()))
)
else:
# 完全分片张量:当前rank拥有完整分片
sharded_weight = ShardedWeight(
flattened_range=slice(0, int(tensor.numel()))
)
目的:为每个优化器状态创建包含完整分片信息的 ShardedWeight 对象。
关键设计思想
1. 分层信息记录
# 记录三个层次的信息:
# 1. 参数级:param_slice_info - 分片范围
# 2. 形状级:param_shape_info - 完整形状
# 3. 全局级:offset_mapping - 全局偏移
2. 分类处理策略
# 三种处理策略:
# 1. 标量参数:直接保存,无需分片信息
# 2. 部分分片张量:记录在完整张量中的位置
# 3. 完全分片张量:当前rank拥有完整分片
3. 全局视角构建
# 每个rank都收集全局信息:
# 1. 所有rank的分片范围
# 2. 完整的参数形状
# 3. 全局偏移映射
2.4 SP(序列并行)
与ColumnParallel、RowParallel类似,只是维度发生在seq_len,且伴随tp(mp)使用。
2.5 关于shared_state_dict方法中structured_name_prefix为空的问题
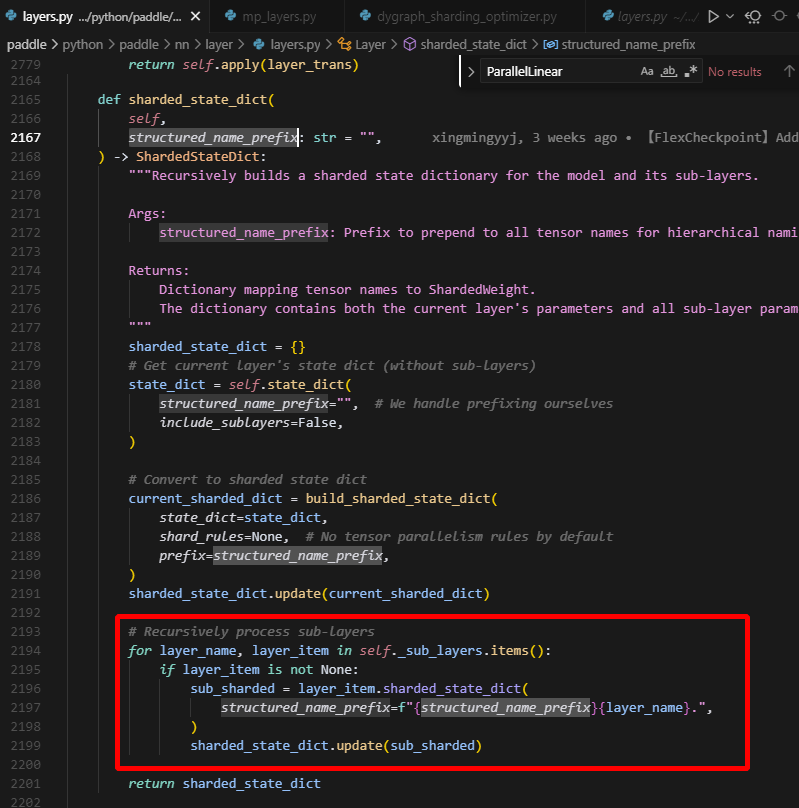
实际上在这里会递归调用sub_layer的shared_state_dict方法,从而将当前层的name传递到sub_layer作为前缀。
3.测试Ernie中的一些问题
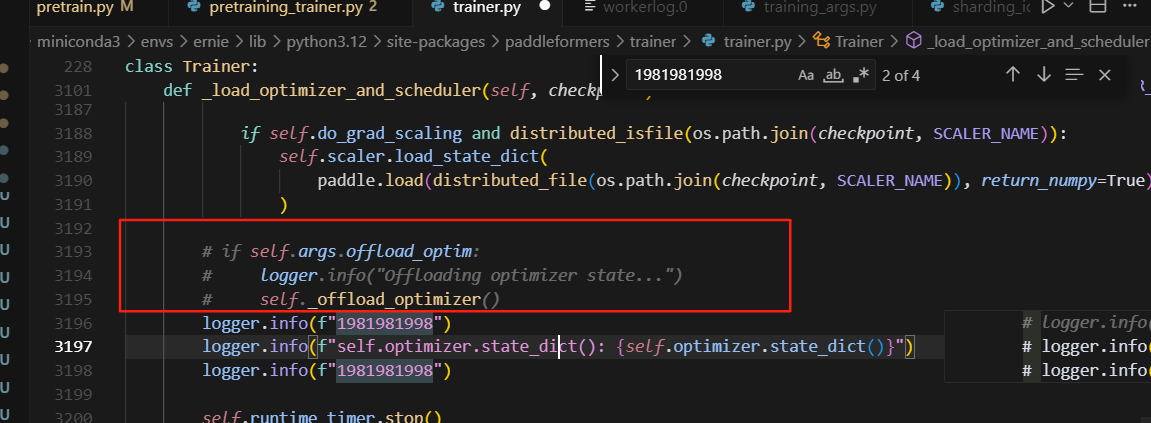
1.self.args.offload_optim
_offlad_optimizer导致保存的转换后的optimizer.pdopt中的动量都没保存成功
模型转换时,如dp2->dp4,offload_optimizer处理后,此时state_dice()中只有master_params和shceduler的数据,动量都被卸载到cpu上了,导致保存失败。
2.sharding4转纯dp2时,文件名不对应,无法加载
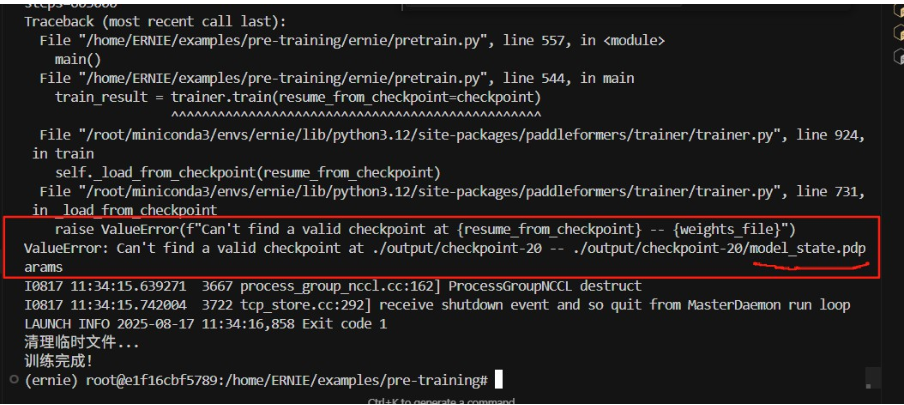
shading对应保存的文件名是model_state_shardxx,但是纯dp加载的model文件名是model_state.paparams,因此保存shading4的ckpt,而此时换成纯dp2训练时,无法正确加载ckpt文件。
3.checkpoint文件路径问题
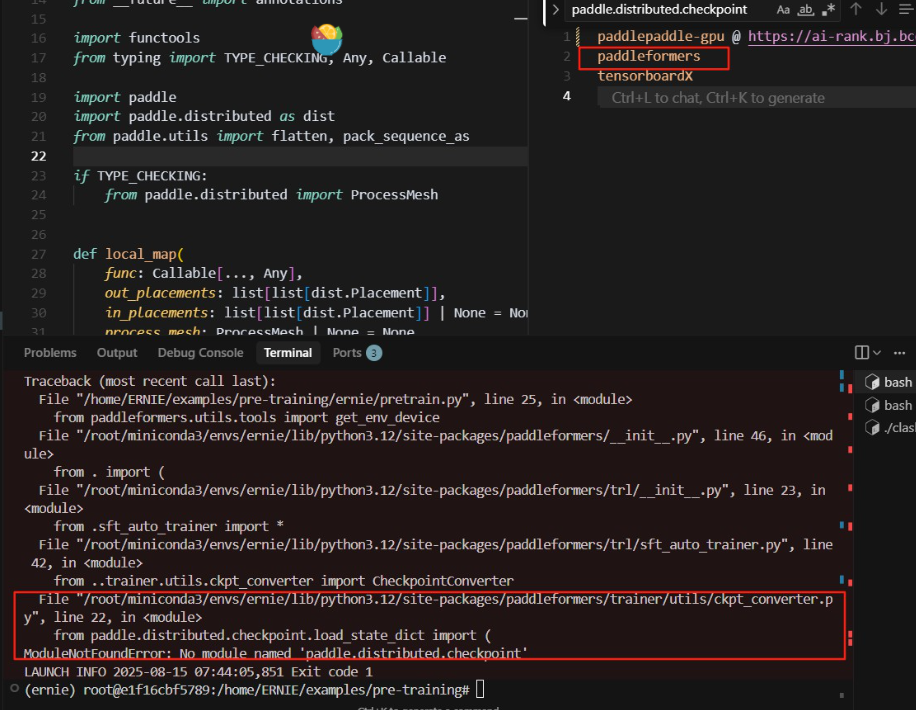
- checkpoint文件路径修改后,paddleformers得同步更新导入得load_state_dict和save_state_dict
4.MoElayer找不到config属性
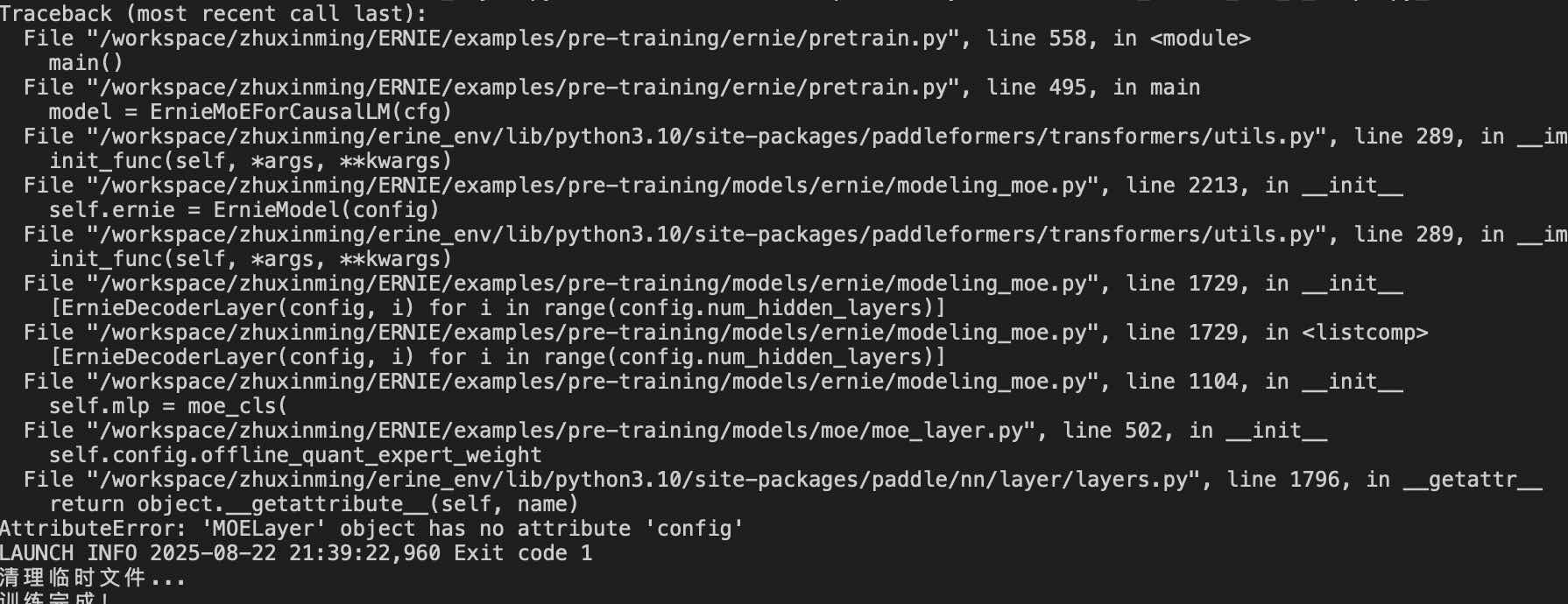
原因:
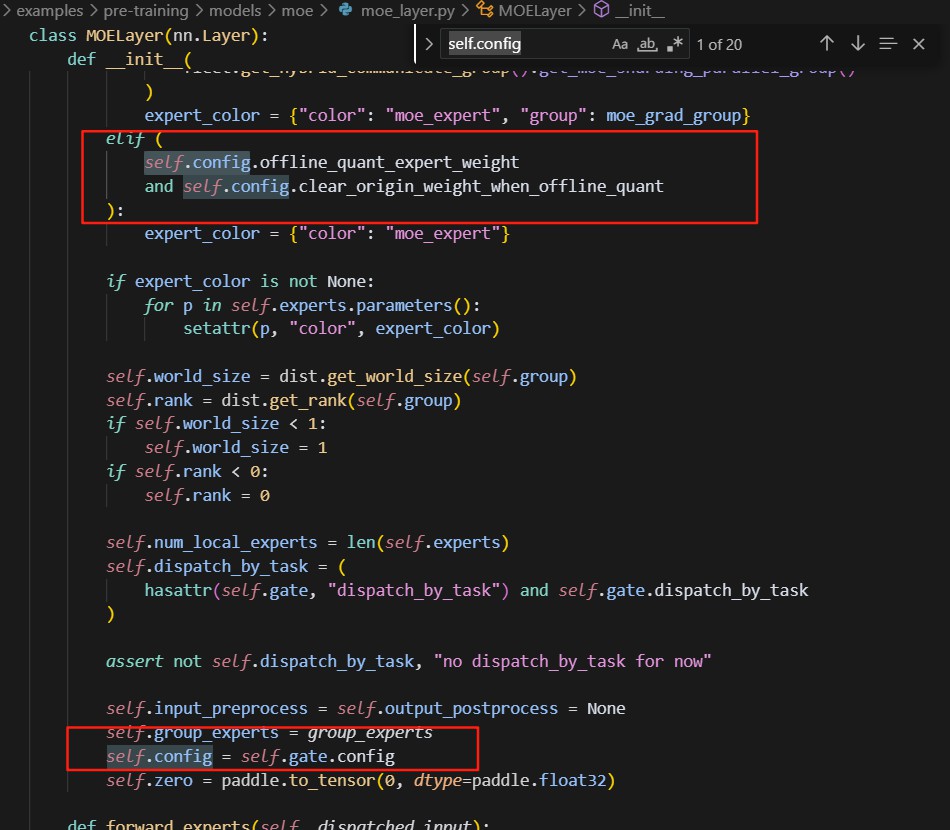
这块是因为还没定义就用了那个config的一些参数,我直接给注释掉了。
5.纯sharding出错,原因是在梯度累加时累加的数据类型有问题
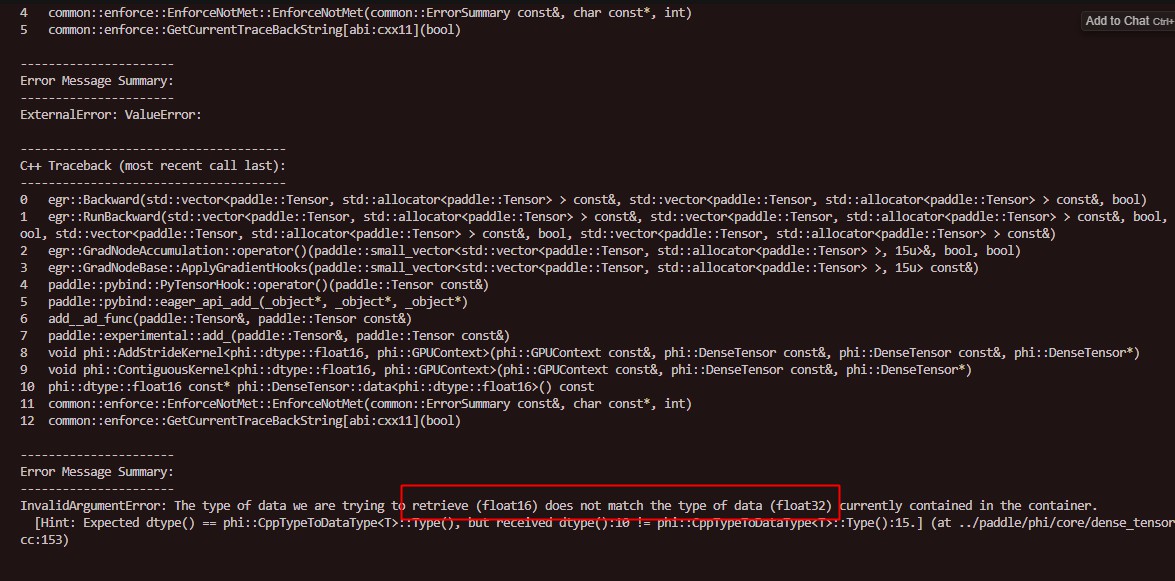
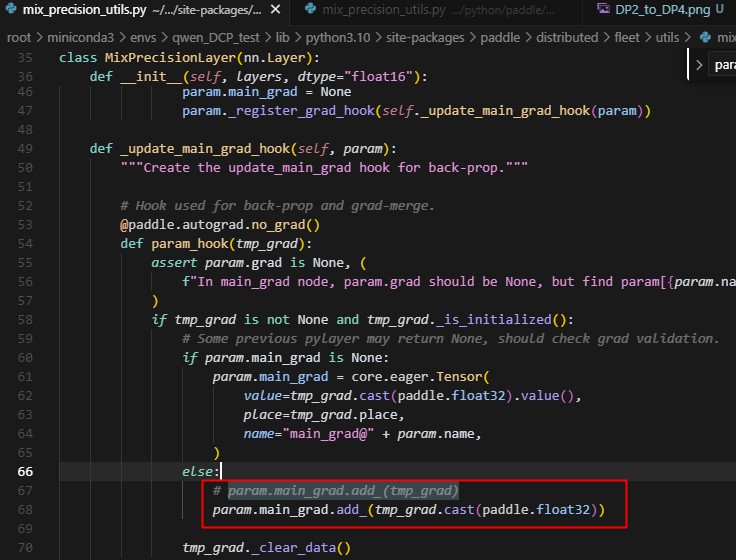
注释掉的为原来的代码,然而测试了最新的paddle发现,add_已经适配了fp16和float32两个不同精度的数相加的场景,估计是当时合入的pr造成的bug,已经被修复。
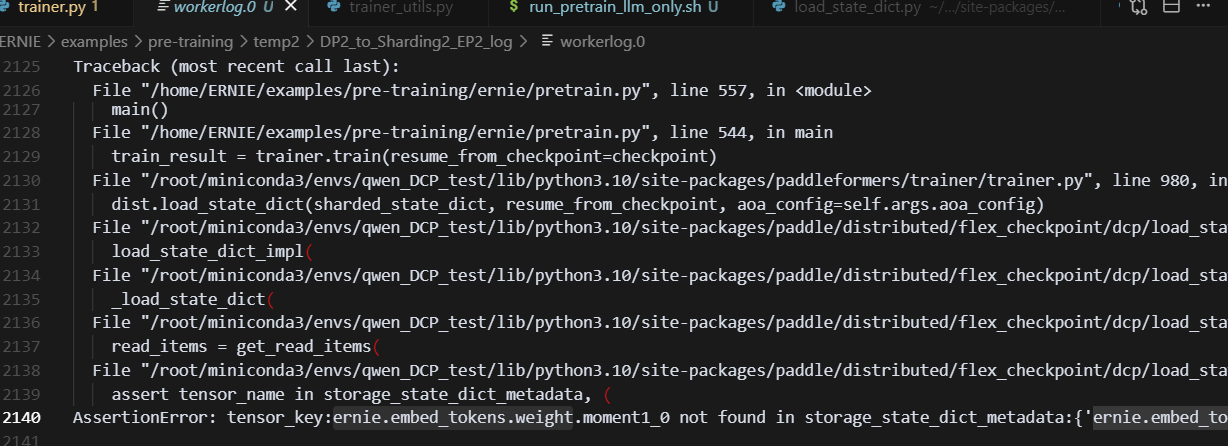
6.t2(ep2)->pp4,报源ckpt加载后的数据,缺少某个参数的优化器状态
lm_head与embedding共享一份weight,因此优化器内部的优化器状态也只有一份
这会导致,在加载ckpt的时候,报错:
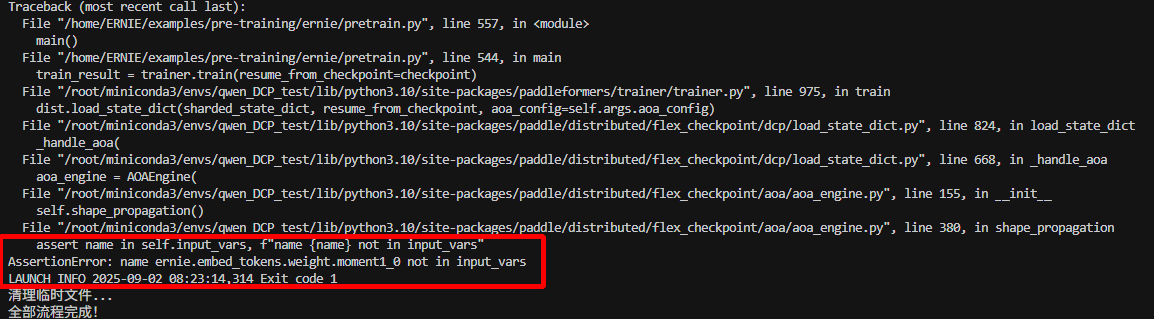
主要原因
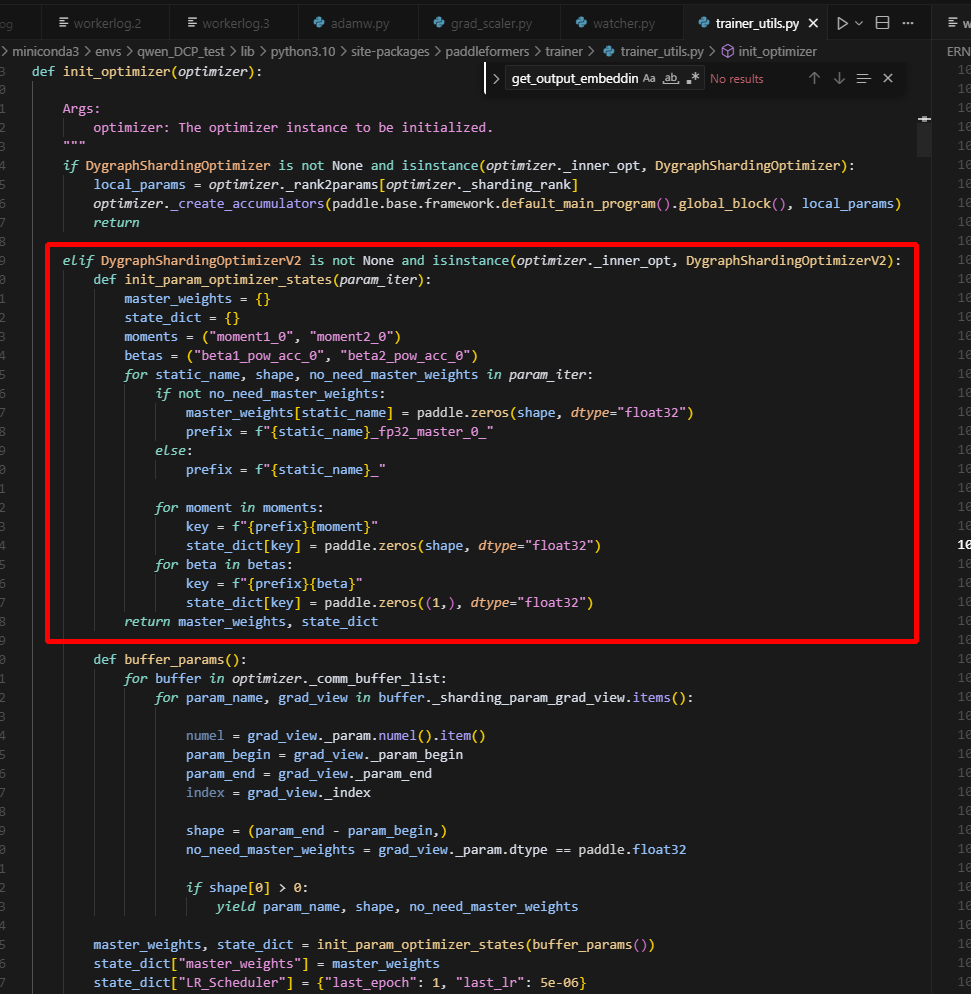
在加载ckpt时,需要初始化model和opt,而使用flex_ckpt框架时,对应的init_opt中是根据model里面的每个key来创建对应的opt状态,,此时embed_layer和lm_head_layer共用同一个参数,因此优化器状态只有一份,所以导致在ckpt中找不到初始化时创建的embed_tokens,导致报错。
问题追溯:
打印出的model及其对应的value:
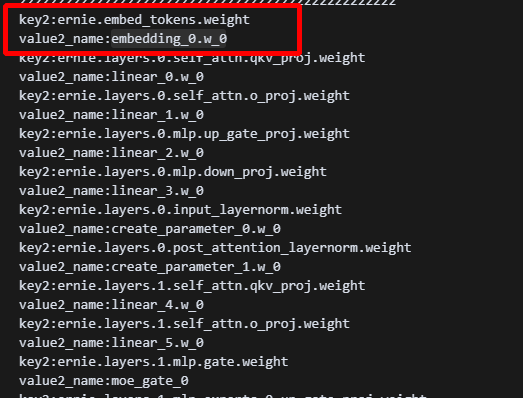

可以看到都指向同一个tensor,而具体实现在tie_weight:
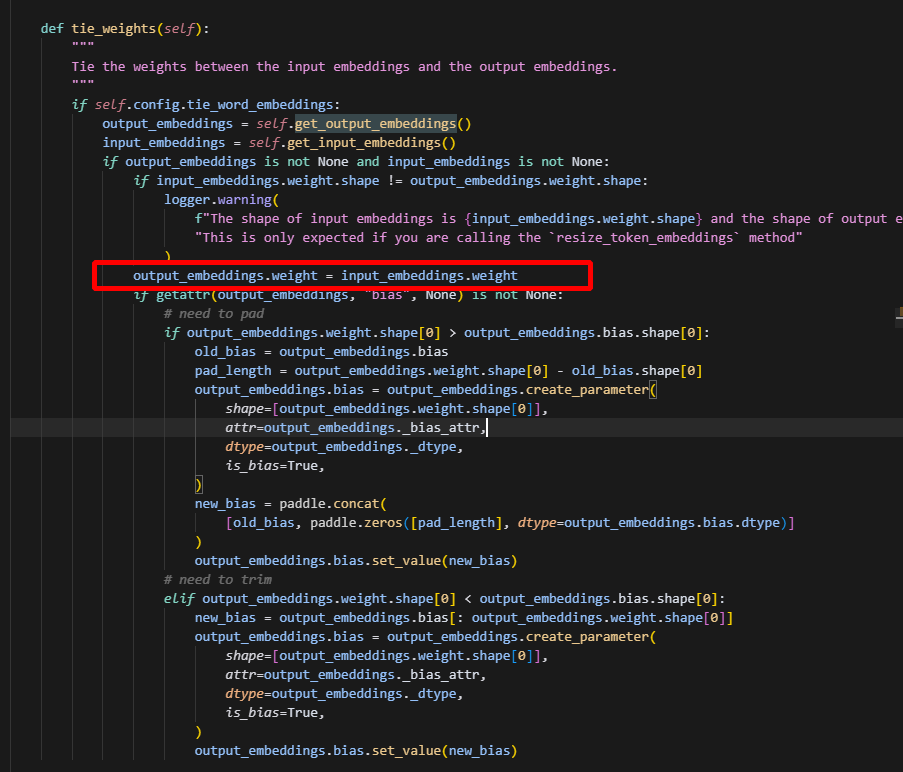
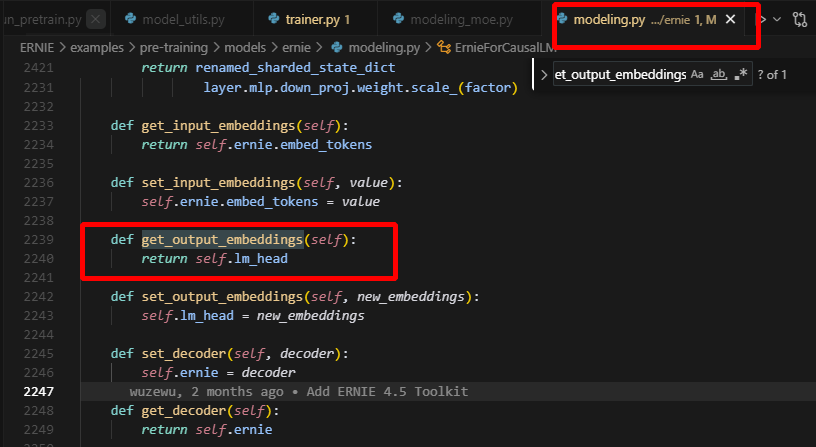
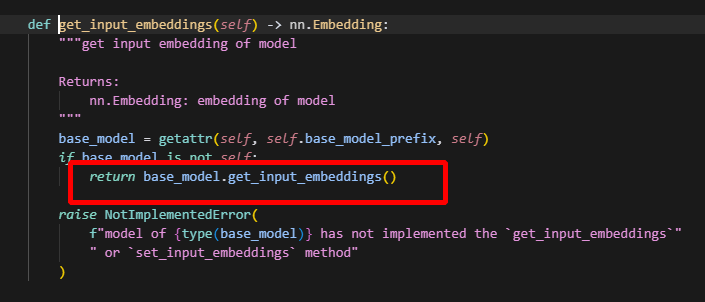
可以看到在这里面将lm_head 直接赋值为embedding对应的tensor
为什么共用一个参数,他们也共用一份优化器状态?
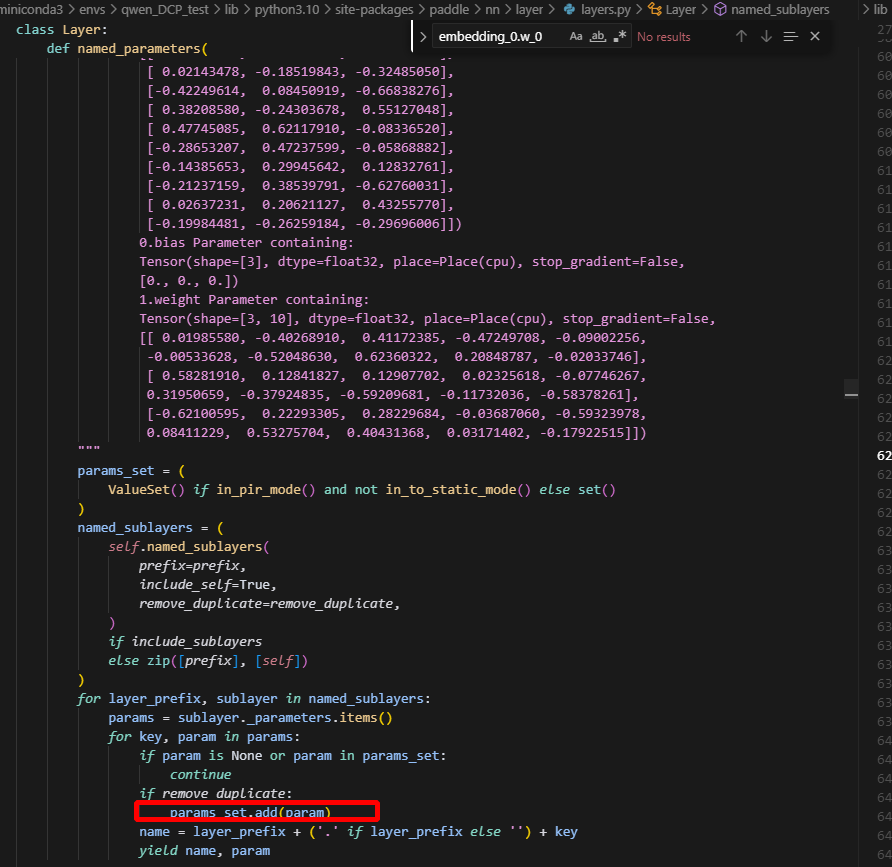
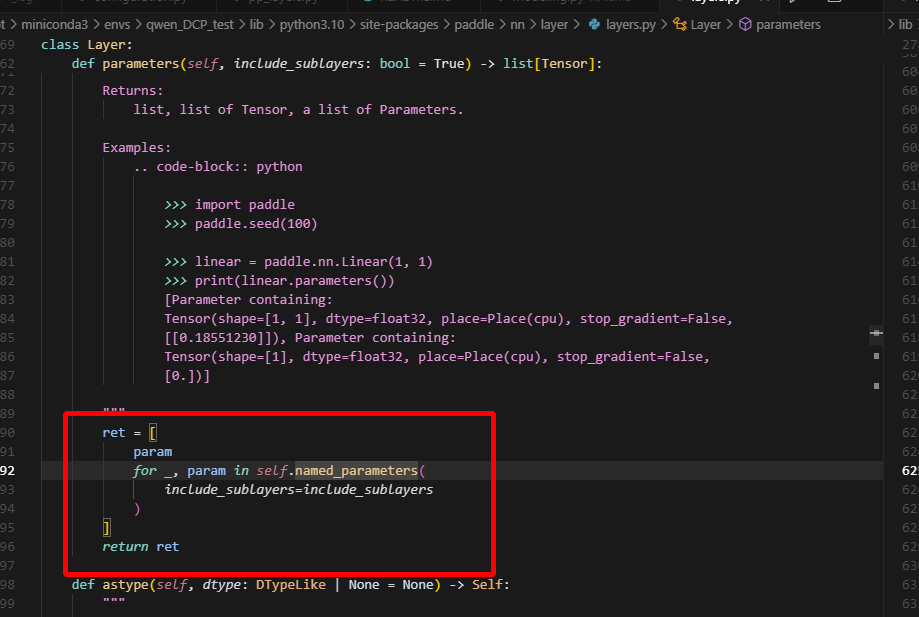
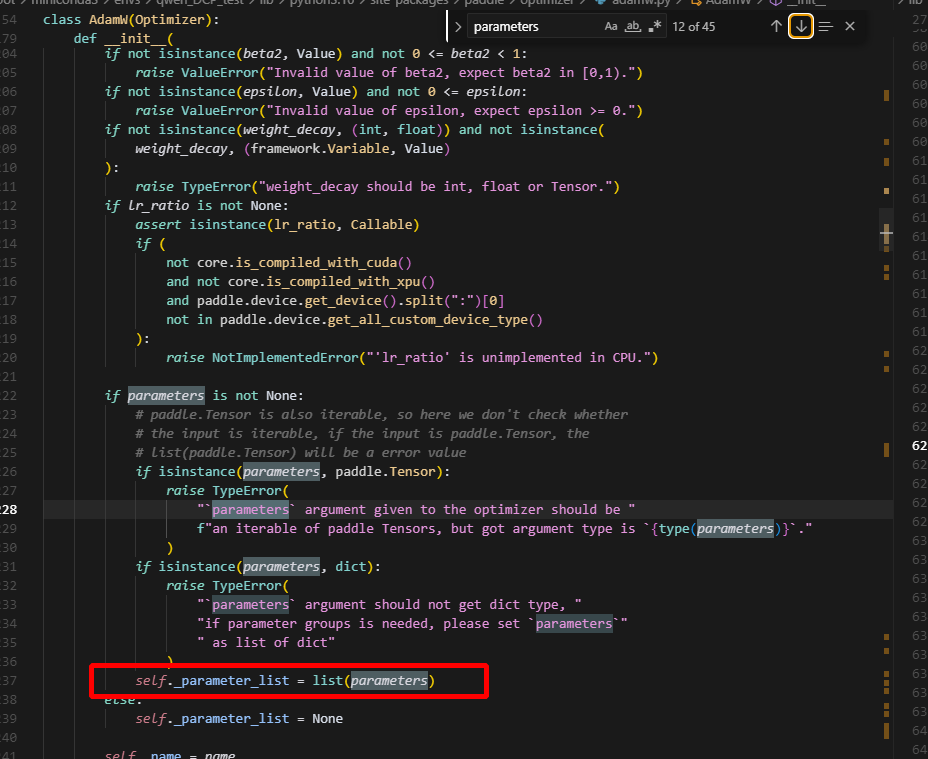
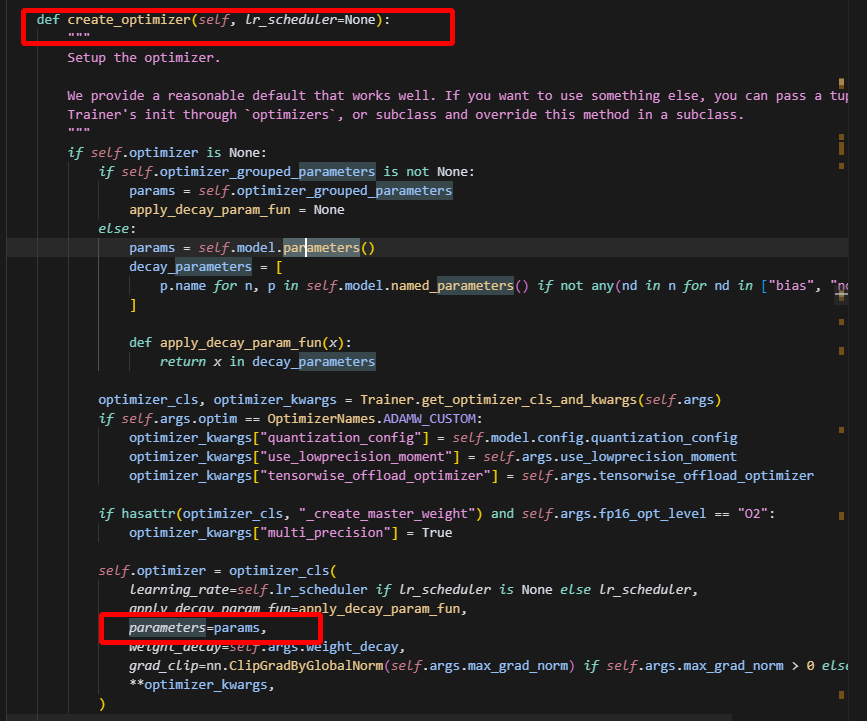
以上是创建optimizer涉及到得流程,可以看到,optimizer中包含的参数,是根据params来去重的,即直接根据Tensor去重,而不是key,因此共享tensor的参数,只会有一份保留在optimizer的参数列表中,并且是第一次出现的参数。
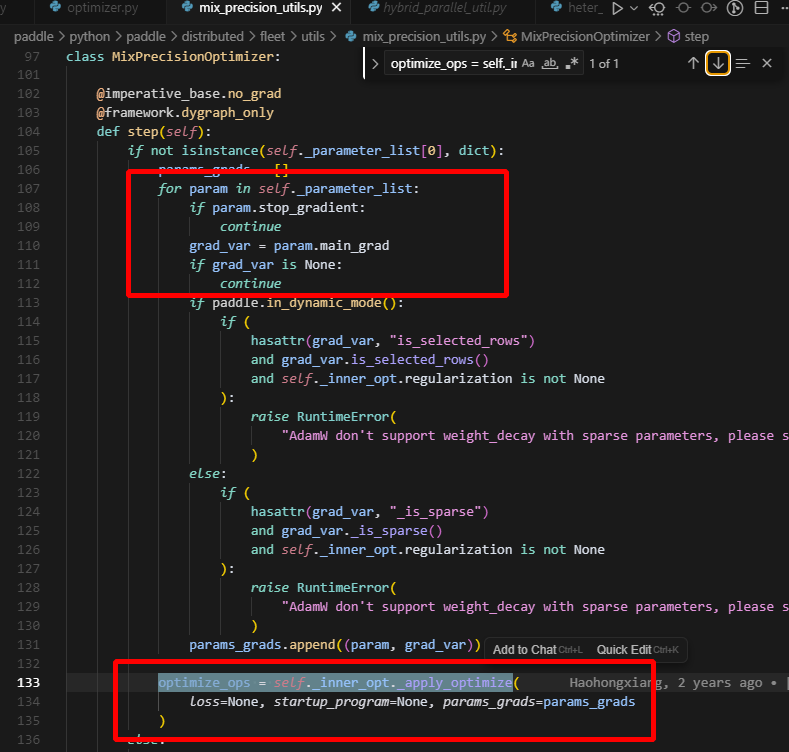
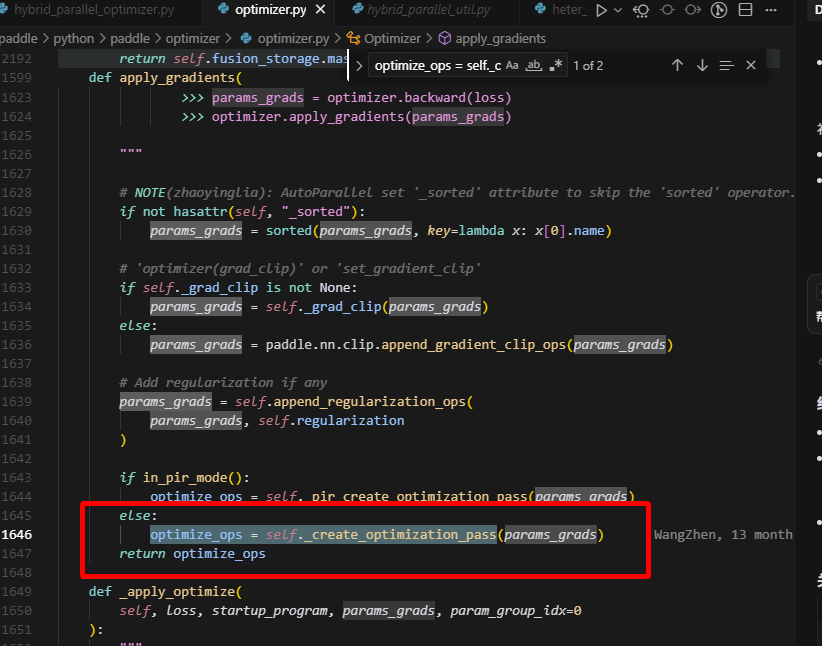
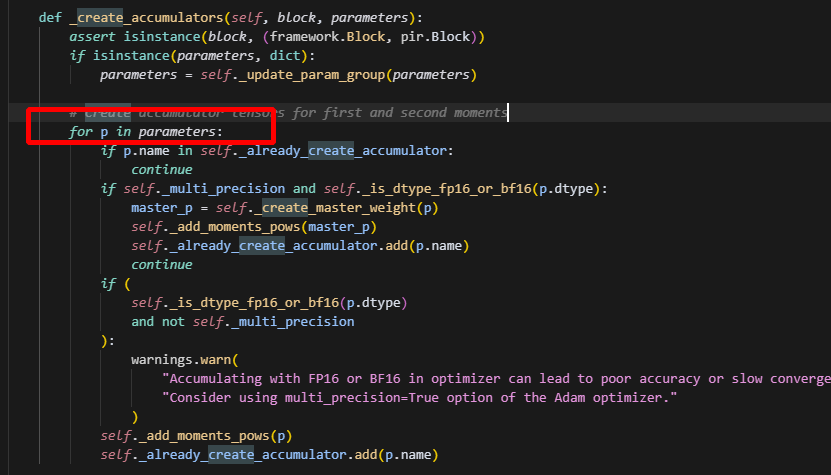
在创建累加器时,此时只有{key:embedding_0.w_0, shared_tensor}保留下来了,所以只有embedding的优化器状态创建了,就不会再创建lm_head的了,打印出来如下:

为什么报错提示找不到embedding的优化器状态,而不是lm_head的优化器状态?
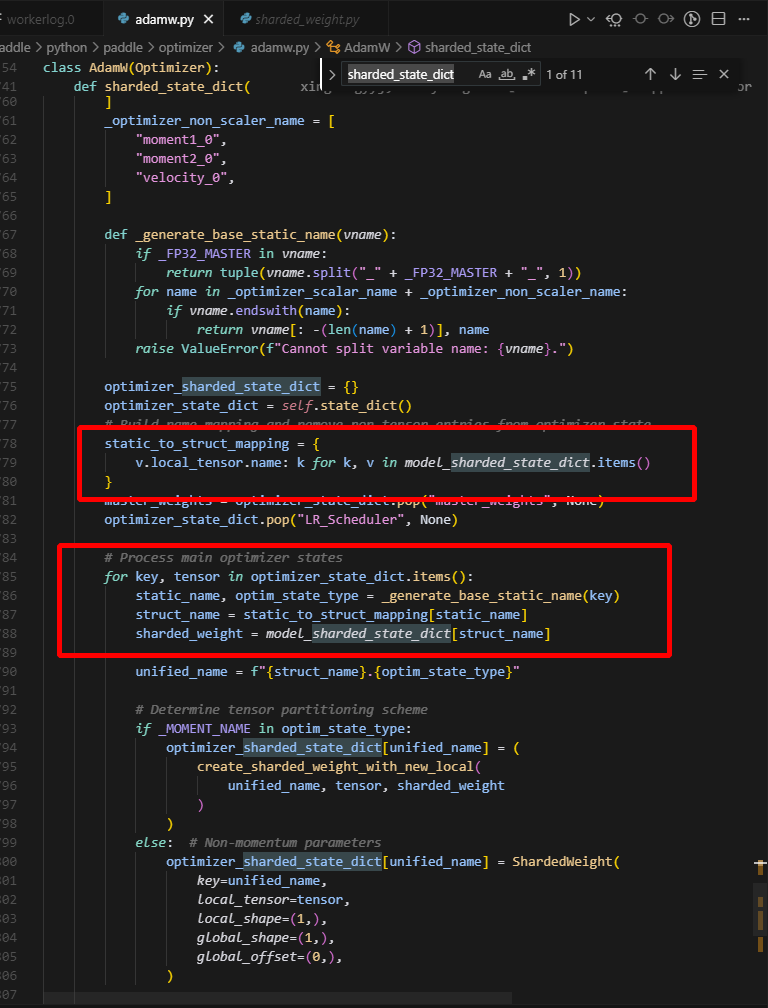
在这里,因为两者的v.local_tensor.name一致,前者被覆盖了。
问题总结:
tp2(ep2)->pp4问题总结: 遇到的问题: 在pp4 load tp2(ep2)保存的ckpt时,加载AOAEngine,调用shape_propagation函数时,未被AOA规则改写的参数会做补全映射,而此时会判断补全的这个key是否在源策略(tp2ep2)中出现过,若没出现过则会报错,而此处就报错:找不到 ernie.embed_tokens.weight.moment1_0(其实所有的embed_tokens.weight相关的优化器状态都找不到)。 原因总结: 在初始化opt的函数中即init_optmizer();会根据当前加载的model参数初始化优化器状态,每一个参数都会为其创建优化器状态,而在ernie4.5非pp的组网中,会使用tie_weight函数使得lm_head与embed相关的两个参数共享同一份tensor,而在训练tp2(ep2)创建优化器状态时,相同param.name的param,只会创建一份优化器状态,并且以第一次出现的key来创建优化器状态参数对应的名称,因此确实lm_head与embed仅仅只有一份权重才对,因此此处是需要优化init_opt部分的逻辑。 然而针对上述逻辑,最终应该是能找到embed相关的优化器状态,而找不到lm相关的优化器状态才对,经过查证,问题在于,AdamW的sharded_state_dict在创建static_to_struct_mapping映射时,未对共用同一个tensor的参数做判断,导致对于共享同一个weight的layer来说,后面layer的参数名(即key)会把前面layer的参数名给覆盖,lm_head在后面,因此覆盖了embed,导致我们在优化器看到的是只有lm_head的优化器状态。因此这里需要优化的是,dygraph_sharding_optimizer和AdamW内的sharded_state_dict函数的逻辑。 但针对ernie的pp组网,查证后发现,并未支持tie_weights操作,lm_head和embed分别独立一份weight;而非pp组网,默认一定调用tie_weights操作,因此在当前情况下,无法做tp2(ep2)->pp4的转换。
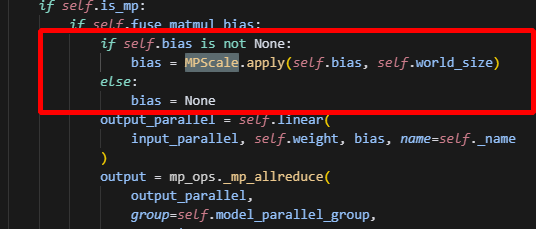
7.bias开false时,会遇到报错
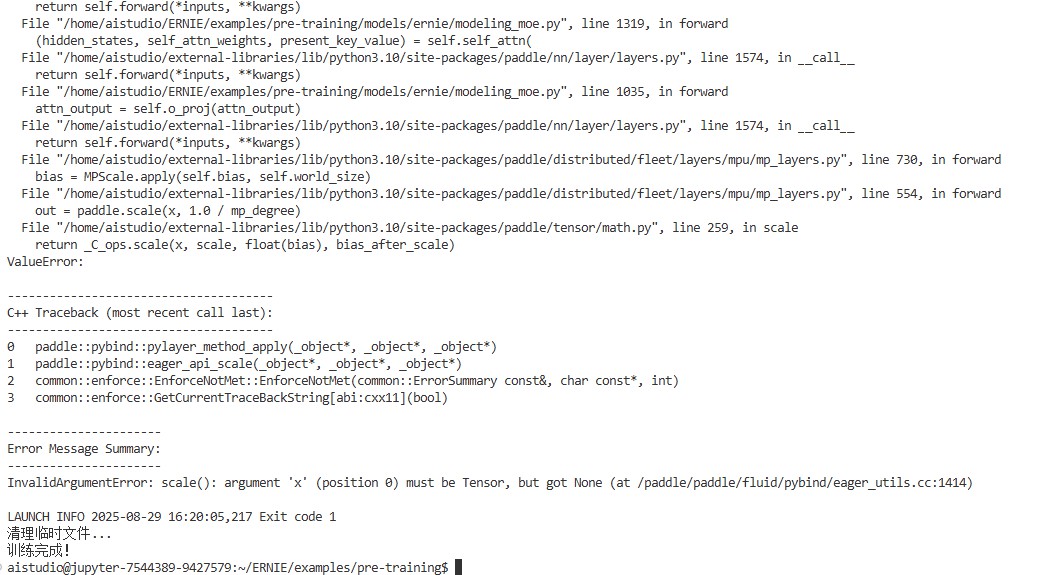
主要原因是,这里直接对bias做scale,然而当bias为None时,是无法做scale的,导致出错。
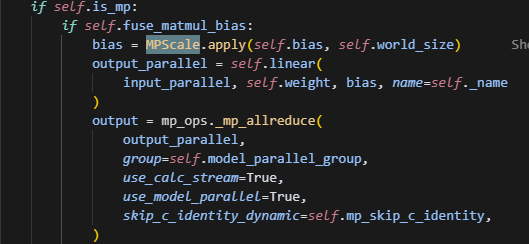
做如下修改即可:
8.测tp2(ep2)->tp4,有一个参数的md5未对齐
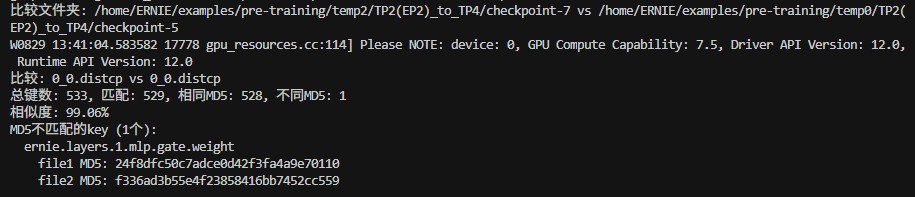
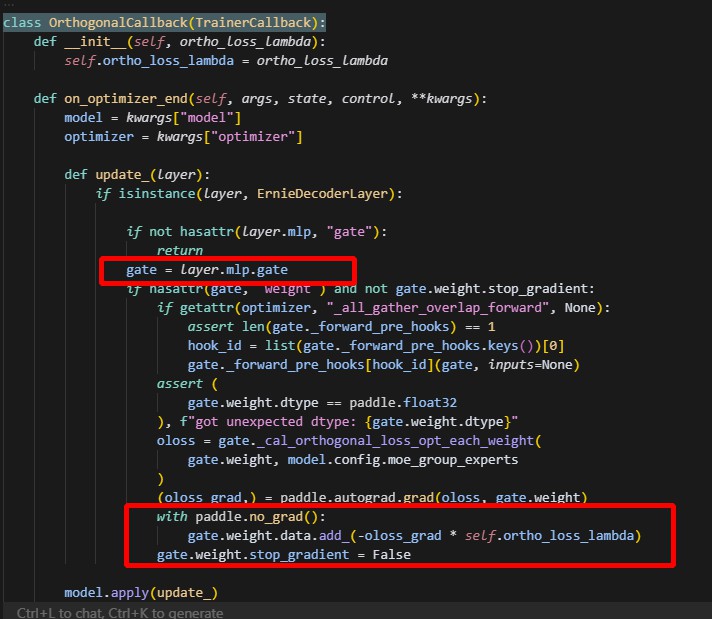
最终总结:FLAGS_shard_bypass_dygraph_optimizer 标志位只能控制优化器本身的参数更新,但无法阻止回调函数中的直接参数操作更新。在 on_optimizer_end 阶段,OrthogonalCallback 会计算正交损失并直接更新 ernie.layers.1.mlp.gate.weight 参数,这种直接参数修改绕过了优化器控制机制,导致该参数在 save/load 转换过程中被意外更新,从而造成 MD5 校验失败。证明了我们的FlexCheckpoint框架逻辑没问题。

9. 测tp2(ep2)->pp4,有多个参数的md5未对齐
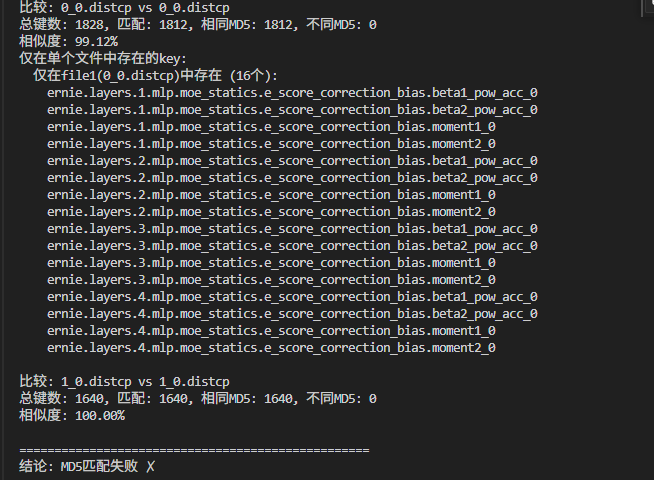
发现是因为moe模式下,开了![]() 的原因,导致moe模式下的模型,会多出一个moe_statics.e_score_correction_bias的参数。
的原因,导致moe模式下的模型,会多出一个moe_statics.e_score_correction_bias的参数。
10.tp2(ep2)转vpp4,暂时有问题,num_hidden_layer配8层,9层都不对
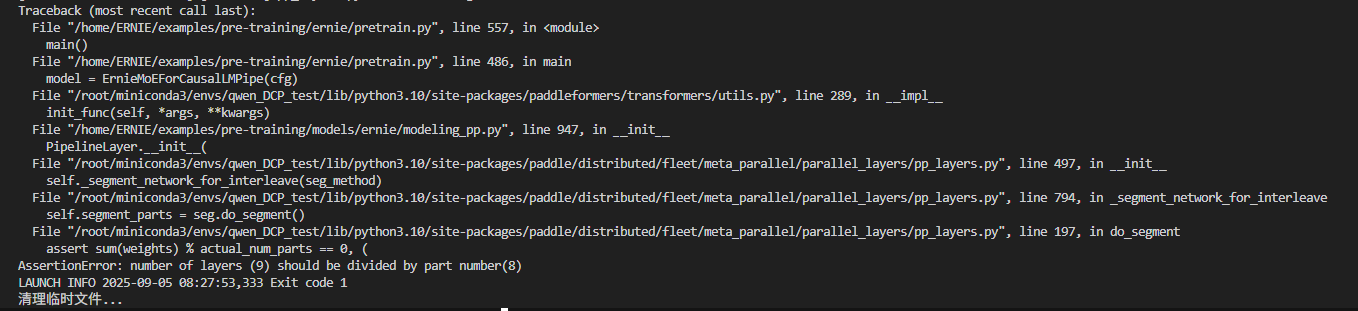
主要是:multi_token_pred_depth参数开启时,会在hidden_layer中多加一层MTP层,导致以下断言不支持,当前ernie4.5的vpp不支持加MTP这一层:
assert sum(weights) % actual_num_parts == 0
但是关掉multi_token_pred_depth参数后,又报p2p通信错误,看起来是ernie4.5跑vpp自身的bug:

11.tp2(ep2)转tp2(ep2)+sd2 和 dp2转tp2(ep2)+sd2时,会出现,某些优化器状态消失得现象
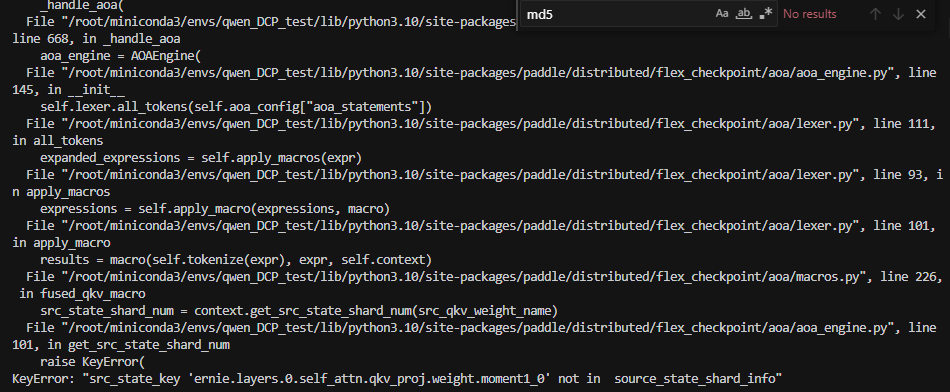
也是开了opitimizer_offload的原因
12.DP2转DP4
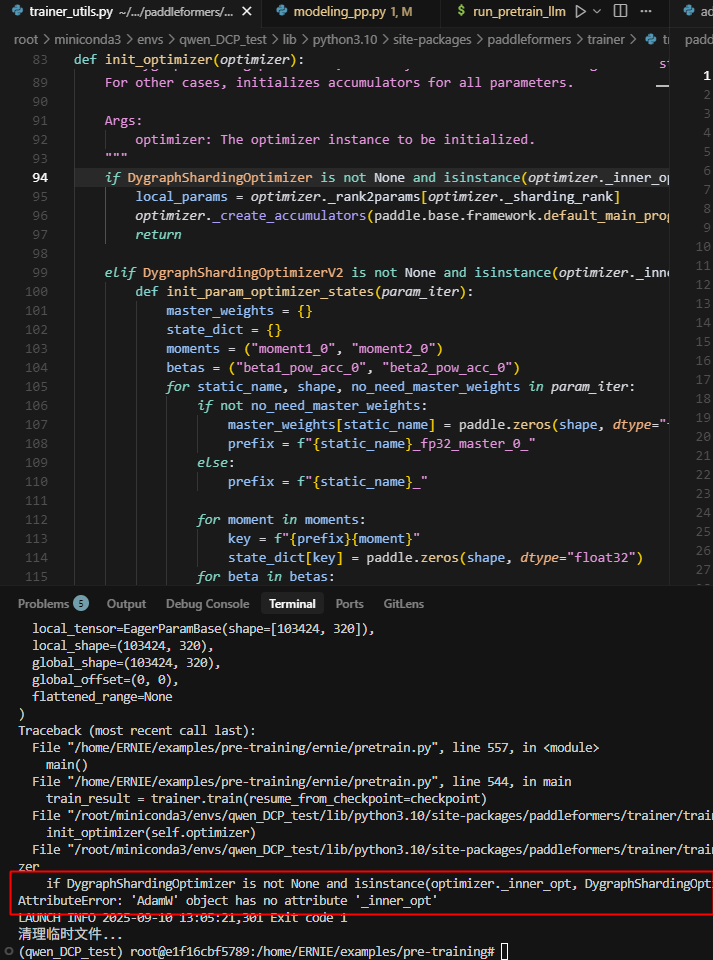
在ernie下跑会报错,因为opt没被封装,它没有inner_opt,而llama下跑不会报错,因为llama下封装了一层:
paddle.distributed.fleet.utils.mix_precision_utils.MixPrecisionOptimizer
因此需要加个判断:
inner_opt = getattr(optimizer, "_inner_opt", None)
if DygraphShardingOptimizer is not None and isinstance(inner_opt, DygraphShardingOptimizer):
local_params = optimizer._rank2params[optimizer._sharding_rank]
optimizer._create_accumulators(paddle.base.framework.default_main_program().global_block(), local_params)
return
elif DygraphShardingOptimizerV2 is not None and isinstance(inner_opt, DygraphShardingOptimizerV2):
注意:ernie4.5训练时,train函数中调用的self._wrap_model是/home/ERNIE/examples/pre-training/ernie/src/trainers/pretraining_trainer.py内的方法。
13.DP2转Sharding4_V1的时候(开dp_group和sharding_group)(验证纯策略需要开dummy)
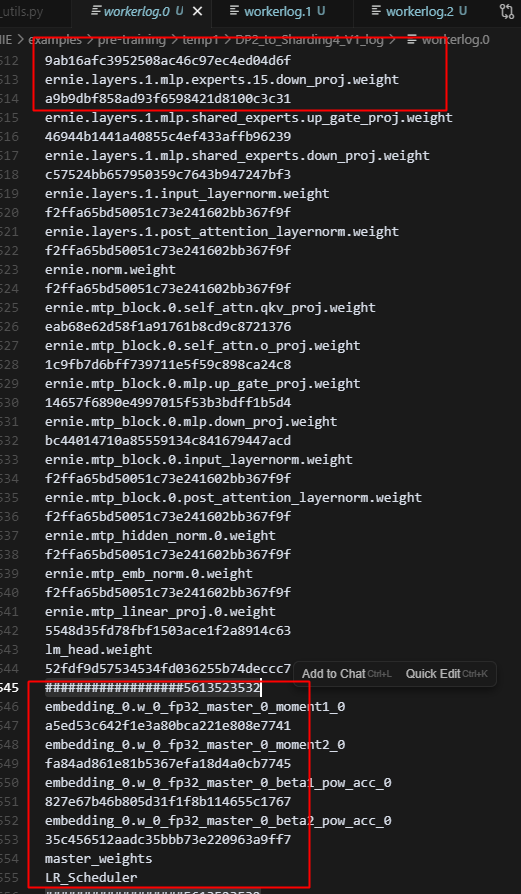
总共64个专家,2卡sharding的时候,只有32个专家有优化器状态,4卡sharding的时候只有16个专家有优化器状态;原因是每个rank上的experts组在训练一次后,所有专家的参数被同步了,未具体定位,但训练5步,4张卡上的16个专家参数的md5完全相同;但初始化时,4张卡上的专家参数是不同的。
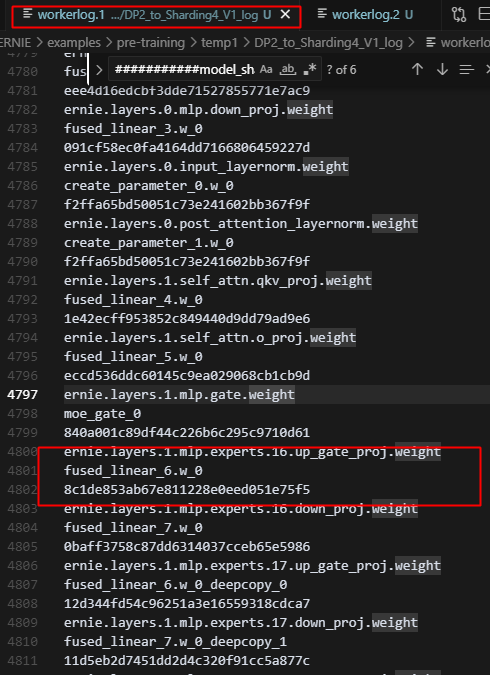
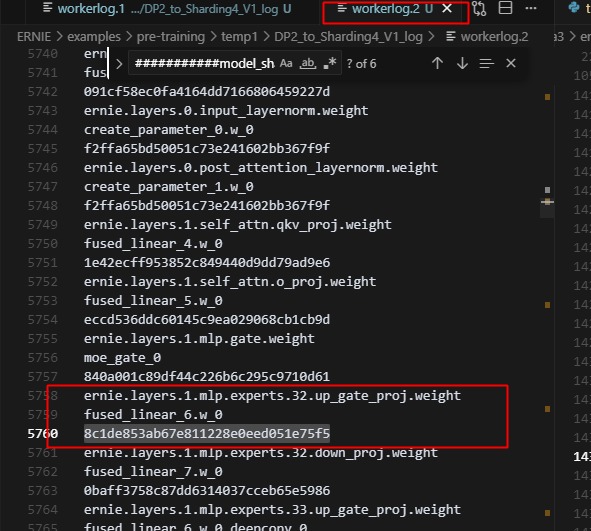
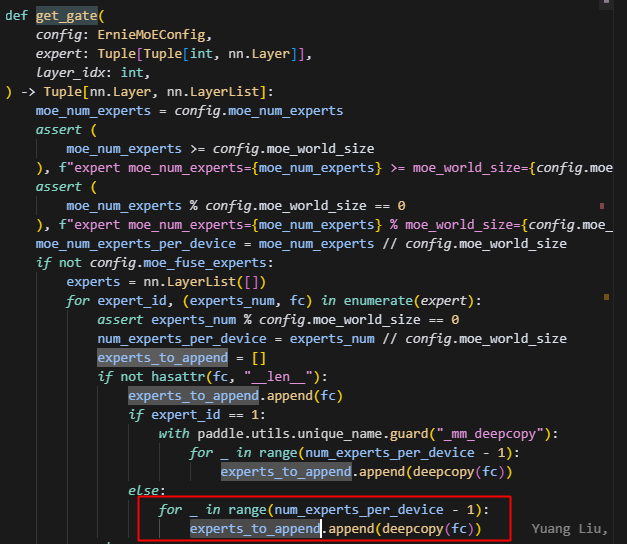
每张卡都做了同样的操作,deepcopy fn,而对每个rank来说,这个fn都是同一个layer。
而DP的时候,每个rank
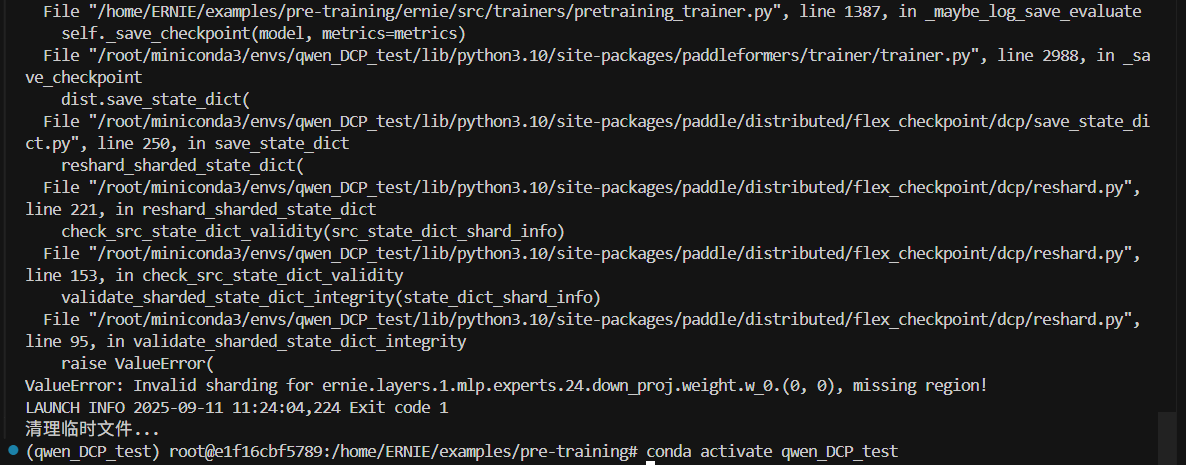
14.DP2转Sharding4_V2的时候
报错如下:
15.DP2转Sharding2_EP2
报错如下,主要是在sharding2_ep2转回dp2时报错,但是接续loss 1E-5对齐:
其实是开了这个的原因
![]()
16.DP2、ShardingV1、V2转TP2(EP2)_PP2
存在下面的报错:
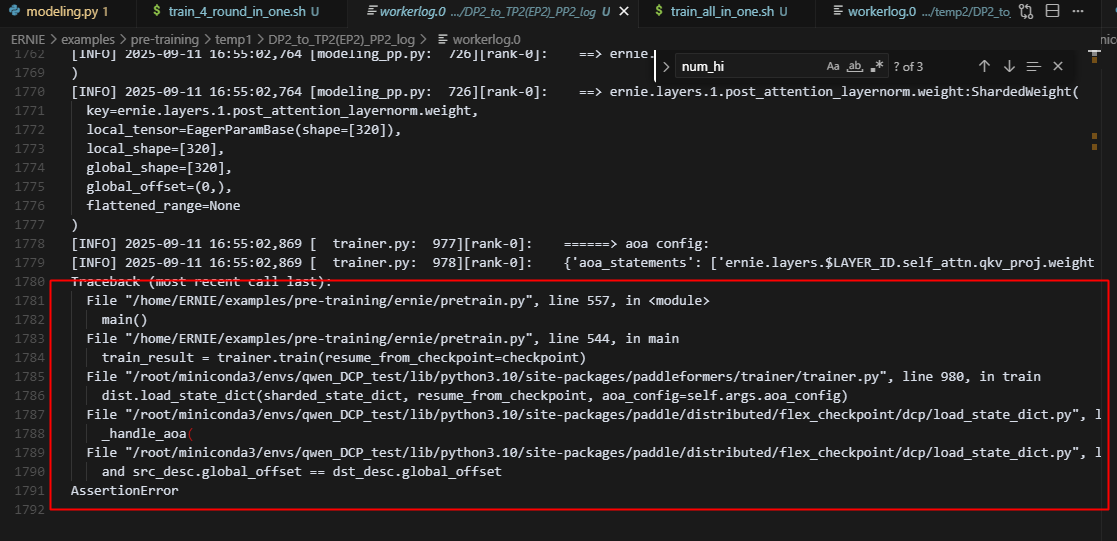
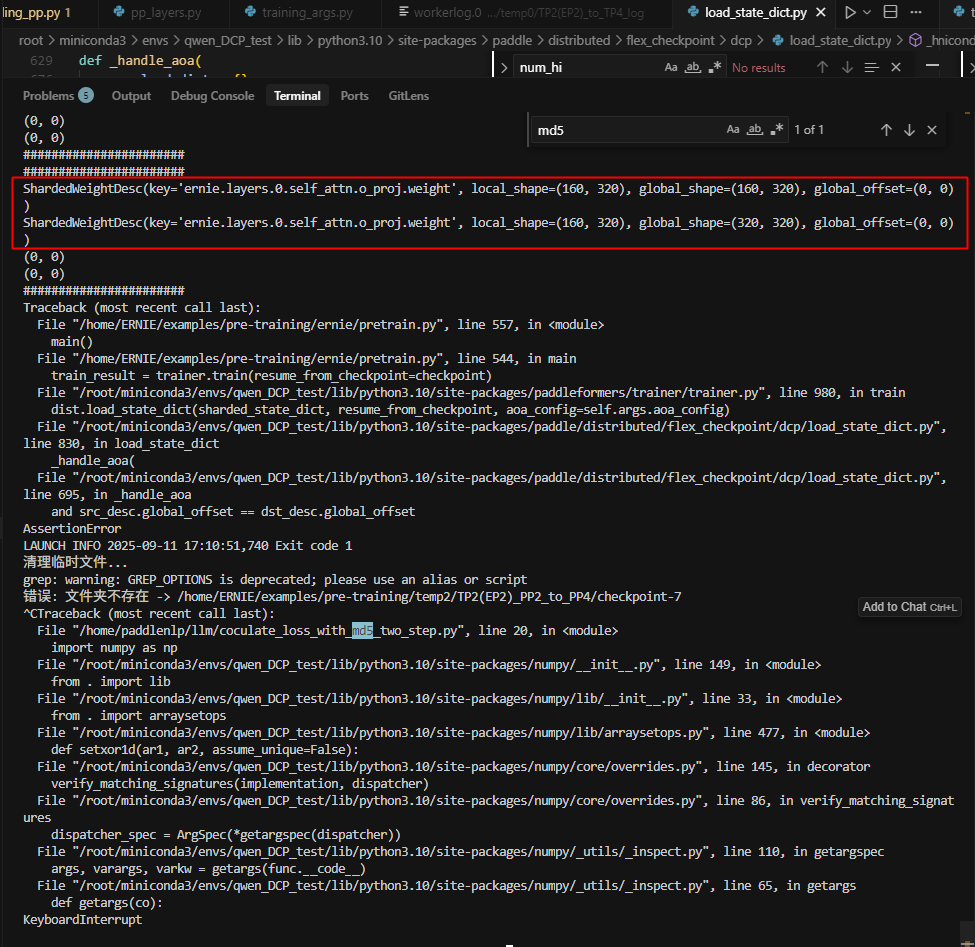
主要原因是ernie4.5中的SequenceParallelLayer没有适配sharded_state_dict
![]()
17.TP2(EP2)跑num_hidden_layer=3的情况时,md5未对齐
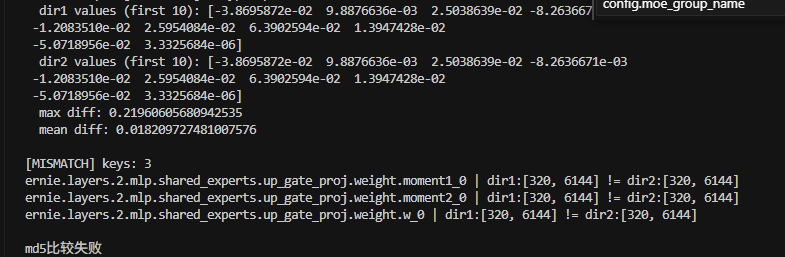
4.测试LLAMA中的一些问题
1.路径需要更换
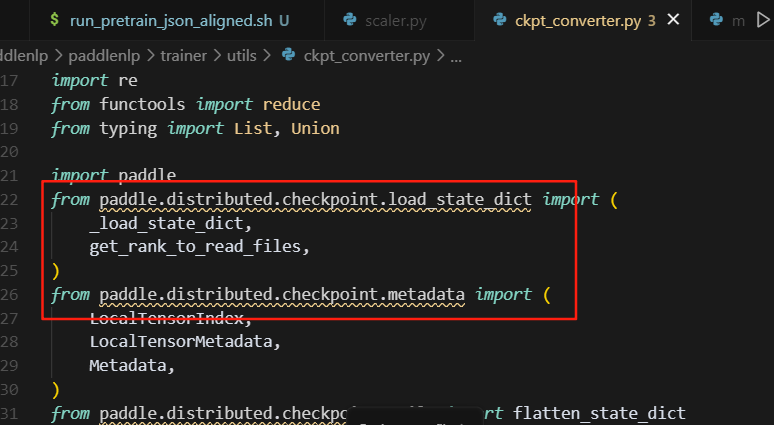
2.sharding__stage_1_overlap不支持
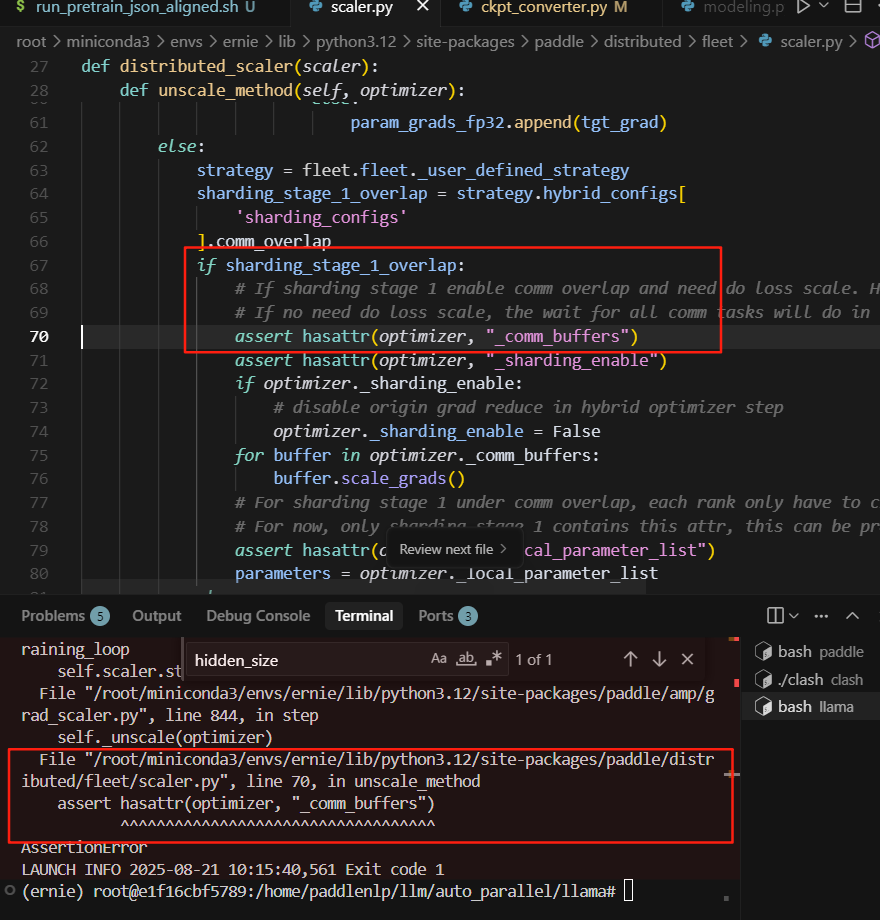
3.纯tp2时报错:
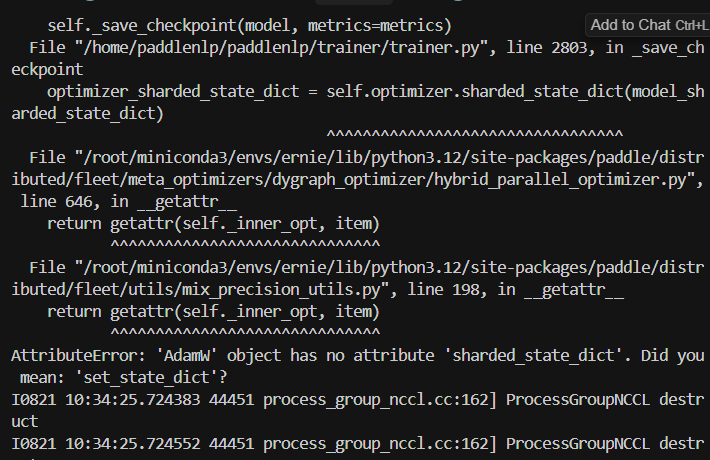
AdamW需要适配sharded_state_dict
4.纯DP下,fleet显示没有正确初始化
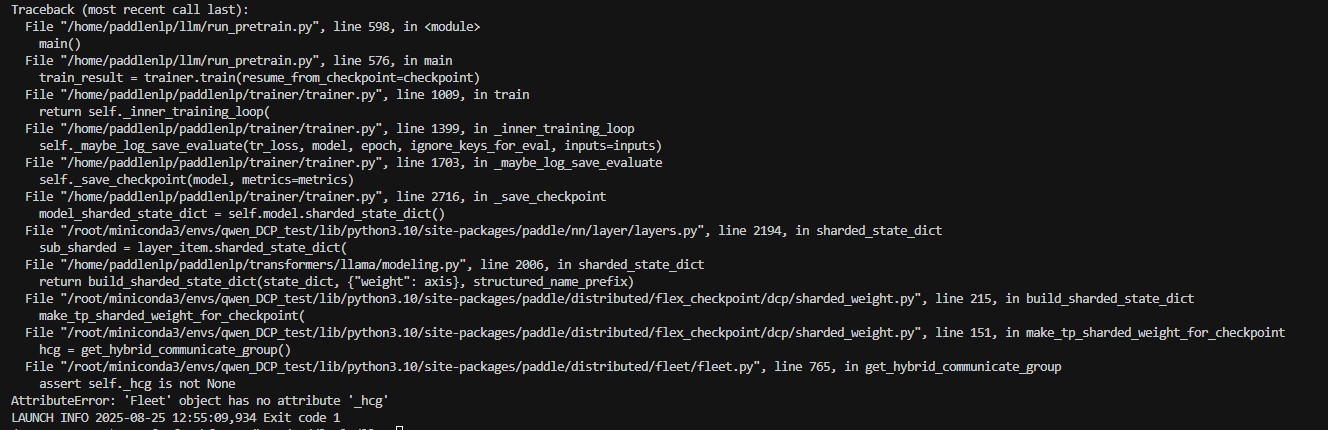
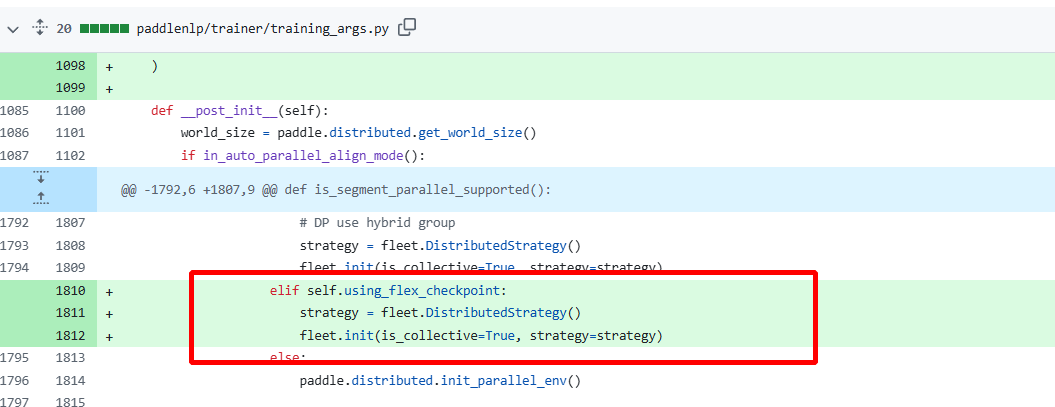
报错的原因是,在纯dp的情况下比较特殊,要开unified_checkpoint这参数,才能用fleet.init初始化,不然用的动半的初始化,这样的话self._hcg没有初始化,就不能调用get_hybrid_communicate_group,加上就好了。
5.纯dp会hang住
现象:
原因:
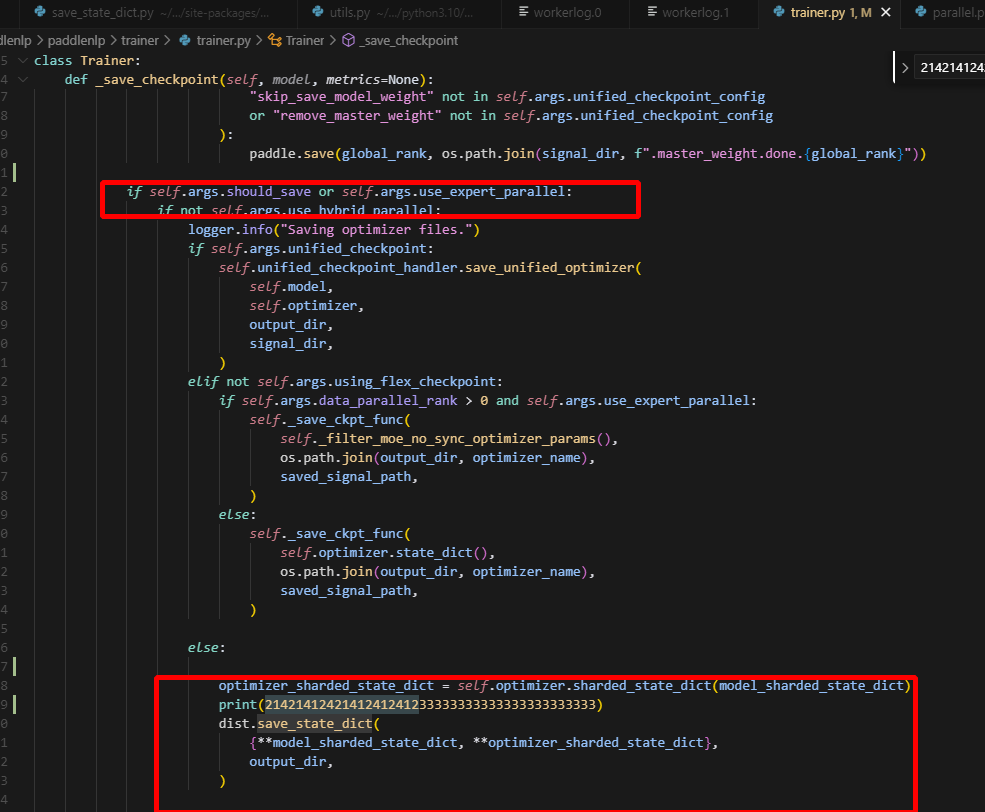
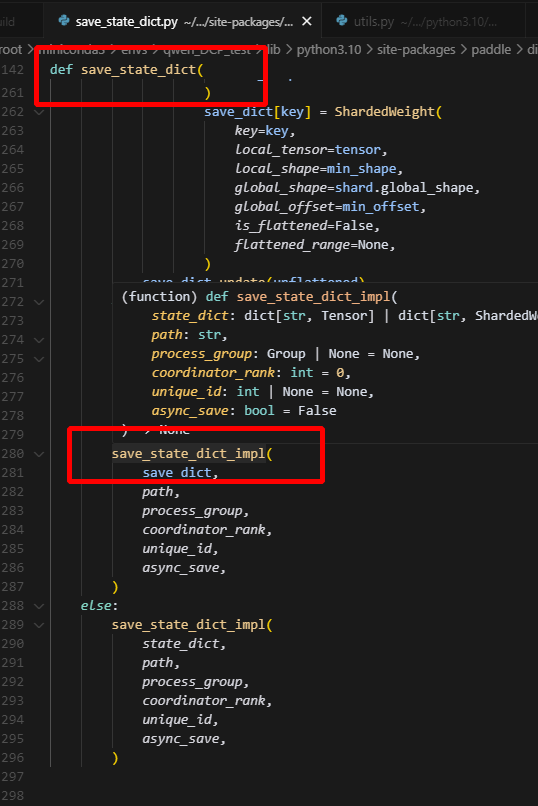
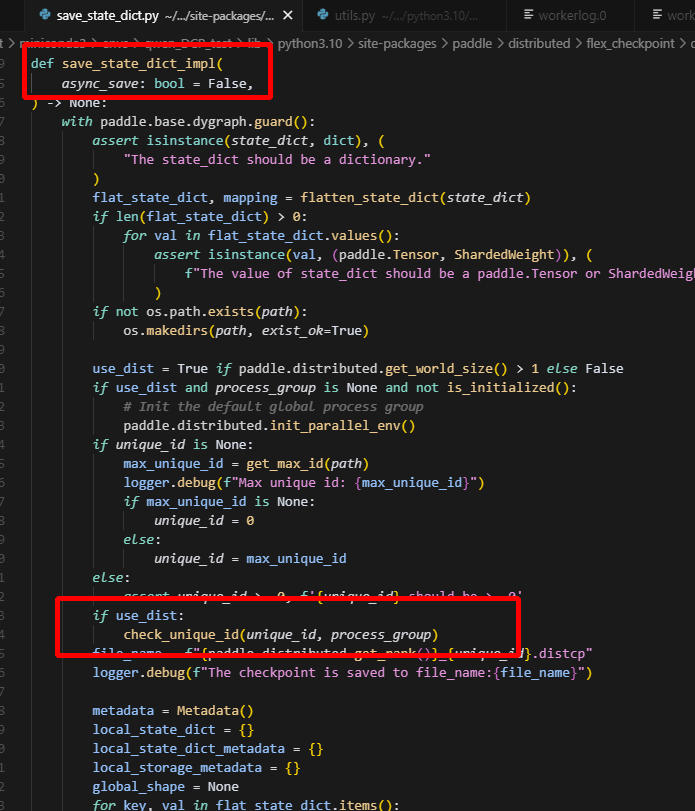
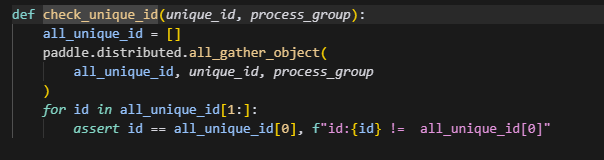
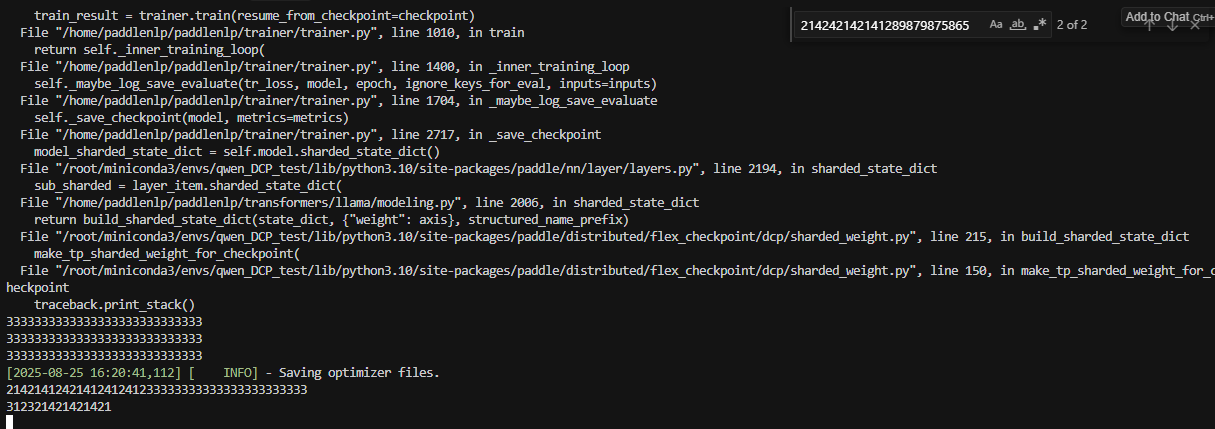
在调用check_unique_id函数时,会调用all_gather获取所有rank的unique_id,而因为纯dp下,should_save被设置为只在0卡保存权重,因此1卡是不会进入save_state_dict中的,而在调用all_gather时,如果process_group为None,则会调用global_group,纯dp2下,即ranks:2 rank_id:0,1;而此时0卡向1卡all_gather请求,1卡却没有做all_gather,0卡就一直等待,最终导致hang住。
解决方案:

添加一个条件,在纯DP时,此时use_hybrid_parallel为false(这是每个rank共同的特征),因此,添加个判断条件,让1卡也进入即可。
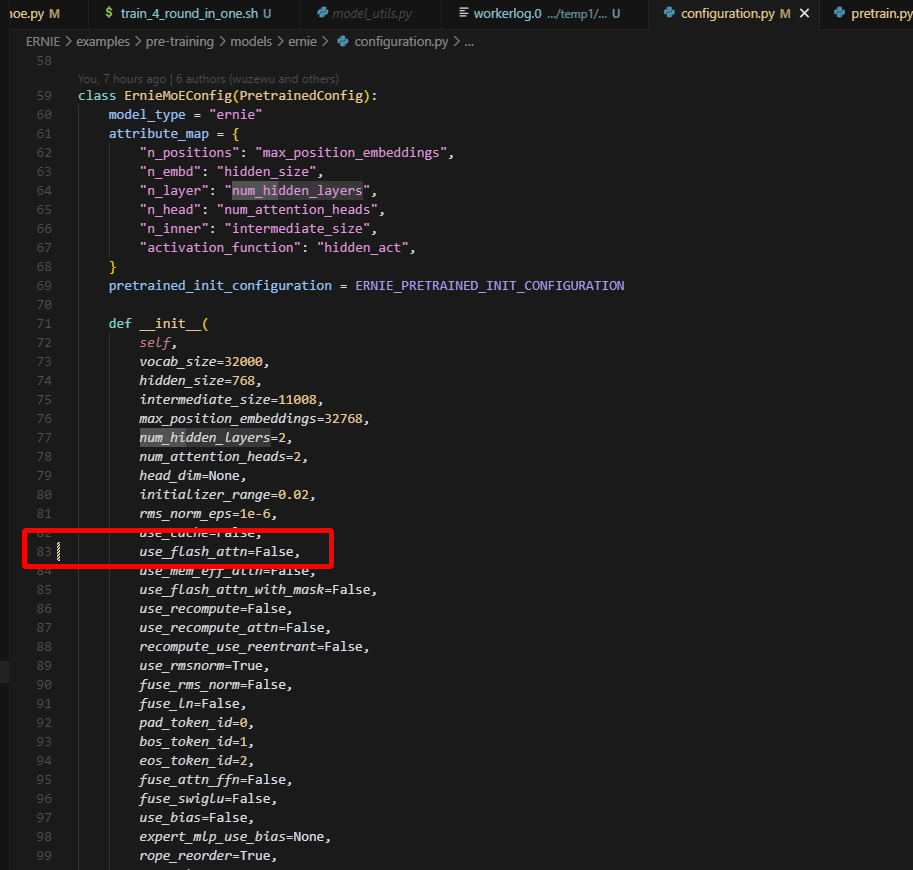
6.flash_attention无法正确传入,要手动修改
7.测tp时,fused_qkv, fused_ffn打开后loss接续不符合预期
在测tp策略转换的过程中,发现fused_qkv, fused_ffn打开后loss差距不符合预期;经验证,当前存在fused_qkv与old_fused_qkv两套逻辑,llama当前默认使用的是old_fused_qkv此时无需配置aoa与tp自洽,而ernie使用的是fused_qkv,需要配置aoa。
llama下的aoa配置:
--aoa_config '{
"aoa_statements": [
"llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight -> llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight, fused_ffn",
"llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight.moment1_0 -> llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight.moment1_0, fused_ffn",
"llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight.moment2_0 -> llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight.moment2_0, fused_ffn",
"llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight.w_0 -> llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight.w_0, fused_ffn"
]
}' \
ernie下的aoa配置:
aoa_config: {
"aoa_statements": [
"ernie.layers.\$LAYER_ID.self_attn.qkv_proj.weight -> ernie.layers.\$LAYER_ID.self_attn.qkv_proj.weight, fused_qkv, num_heads=20, num_key_value_groups=5",
"ernie.layers.\$LAYER_ID.self_attn.qkv_proj.weight.moment1_0 -> ernie.layers.\$LAYER_ID.self_attn.qkv_proj.weight.moment1_0, fused_qkv, num_heads=20, num_key_value_groups=5",
"ernie.layers.\$LAYER_ID.self_attn.qkv_proj.weight.moment2_0 -> ernie.layers.\$LAYER_ID.self_attn.qkv_proj.weight.moment2_0, fused_qkv, num_heads=20, num_key_value_groups=5",
"ernie.layers.\$LAYER_ID.self_attn.qkv_proj.weight.w_0 -> ernie.layers.\$LAYER_ID.self_attn.qkv_proj.weight.w_0, fused_qkv, num_heads=20, num_key_value_groups=5",
"ernie.mtp_block.\$LAYER_ID.self_attn.qkv_proj.weight -> ernie.mtp_block.\$LAYER_ID.self_attn.qkv_proj.weight, fused_qkv, num_heads=20, num_key_value_groups=5",
"ernie.mtp_block.\$LAYER_ID.self_attn.qkv_proj.weight.moment1_0 -> ernie.mtp_block.\$LAYER_ID.self_attn.qkv_proj.weight.moment1_0, fused_qkv, num_heads=20, num_key_value_groups=5",
"ernie.mtp_block.\$LAYER_ID.self_attn.qkv_proj.weight.moment2_0 -> ernie.mtp_block.\$LAYER_ID.self_attn.qkv_proj.weight.moment2_0, fused_qkv, num_heads=20, num_key_value_groups=5",
"ernie.mtp_block.\$LAYER_ID.self_attn.qkv_proj.weight.w_0 -> ernie.mtp_block.\$LAYER_ID.self_attn.qkv_proj.weight.w_0, fused_qkv, num_heads=20, num_key_value_groups=5",
"ernie.layers.\$LAYER_ID.mlp.up_gate_proj.weight -> ernie.layers.\$LAYER_ID.mlp.up_gate_proj.weight, fused_ffn",
"ernie.layers.\$LAYER_ID.mlp.up_gate_proj.weight.moment1_0 -> ernie.layers.\$LAYER_ID.mlp.up_gate_proj.weight.moment1_0, fused_ffn",
"ernie.layers.\$LAYER_ID.mlp.up_gate_proj.weight.moment2_0 -> ernie.layers.\$LAYER_ID.mlp.up_gate_proj.weight.moment2_0, fused_ffn",
"ernie.layers.\$LAYER_ID.mlp.up_gate_proj.weight.w_0 -> ernie.layers.\$LAYER_ID.mlp.up_gate_proj.weight.w_0, fused_ffn",
"ernie.mtp_block.\$LAYER_ID.mlp.up_gate_proj.weight -> ernie.mtp_block.\$LAYER_ID.mlp.up_gate_proj.weight, fused_ffn",
"ernie.mtp_block.\$LAYER_ID.mlp.up_gate_proj.weight.moment1_0 -> ernie.mtp_block.\$LAYER_ID.mlp.up_gate_proj.weight.moment1_0, fused_ffn",
"ernie.mtp_block.\$LAYER_ID.mlp.up_gate_proj.weight.moment2_0 -> ernie.mtp_block.\$LAYER_ID.mlp.up_gate_proj.weight.moment2_0, fused_ffn",
"ernie.mtp_block.\$LAYER_ID.mlp.up_gate_proj.weight.w_0 -> ernie.mtp_block.\$LAYER_ID.mlp.up_gate_proj.weight.w_0, fused_ffn",
"ernie.layers.1.mlp.shared_experts.up_gate_proj.weight -> ernie.layers.1.mlp.shared_experts.up_gate_proj.weight, fused_ffn",
"ernie.layers.1.mlp.shared_experts.up_gate_proj.weight.moment1_0 -> ernie.layers.1.mlp.shared_experts.up_gate_proj.weight.moment1_0, fused_ffn",
"ernie.layers.1.mlp.shared_experts.up_gate_proj.weight.moment2_0 -> ernie.layers.1.mlp.shared_experts.up_gate_proj.weight.moment2_0, fused_ffn",
"ernie.layers.1.mlp.shared_experts.up_gate_proj.weight.w_0 -> ernie.layers.1.mlp.shared_experts.up_gate_proj.weight.w_0, fused_ffn",
]
}
fused_qkv(llama)实现逻辑图:
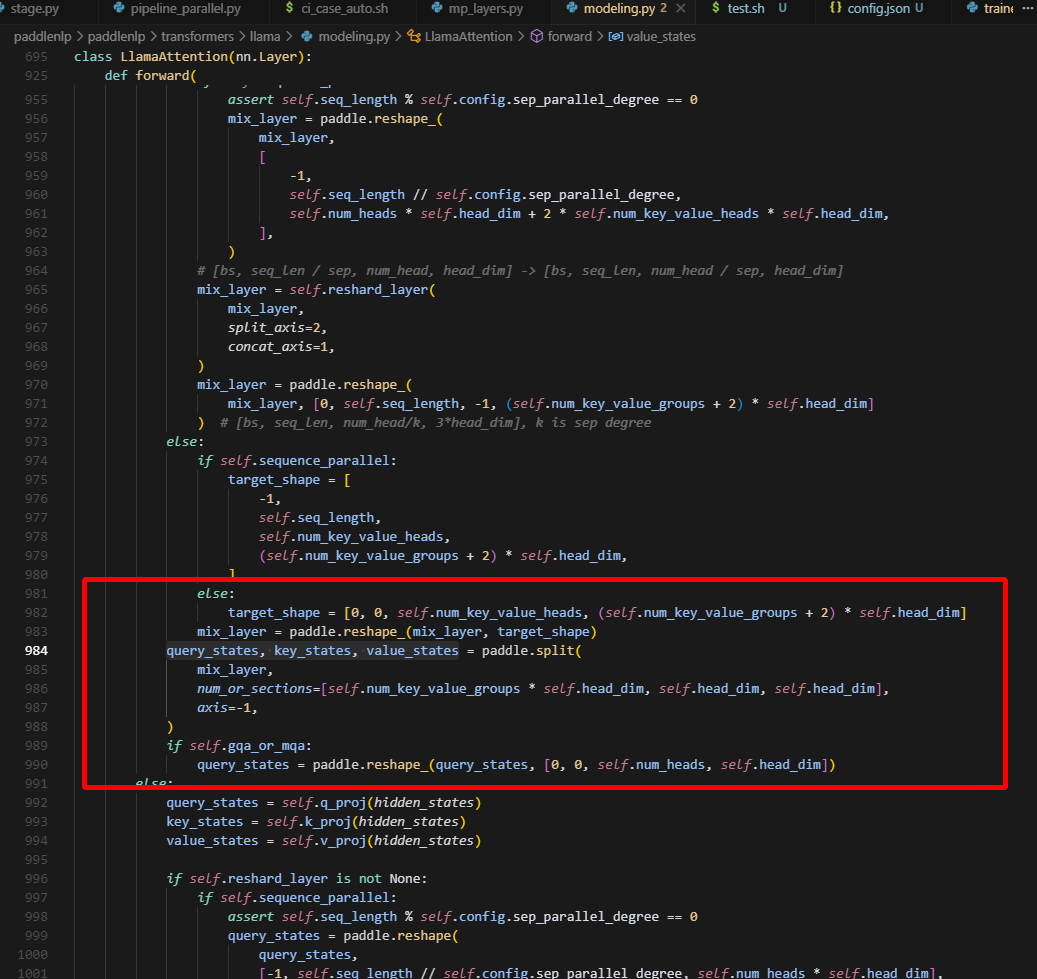
tp2->tp4,num_heads=k_v_nums:
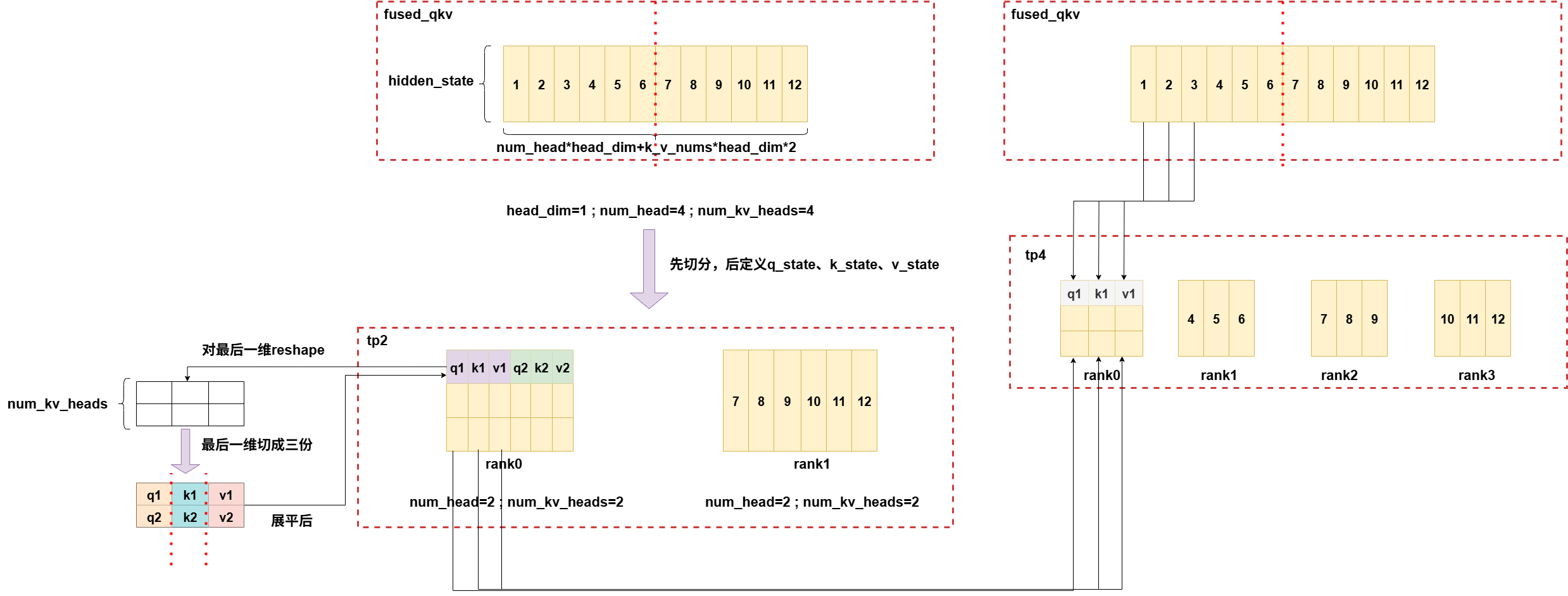
tp2->tp4,num_heads>k_v_nums:
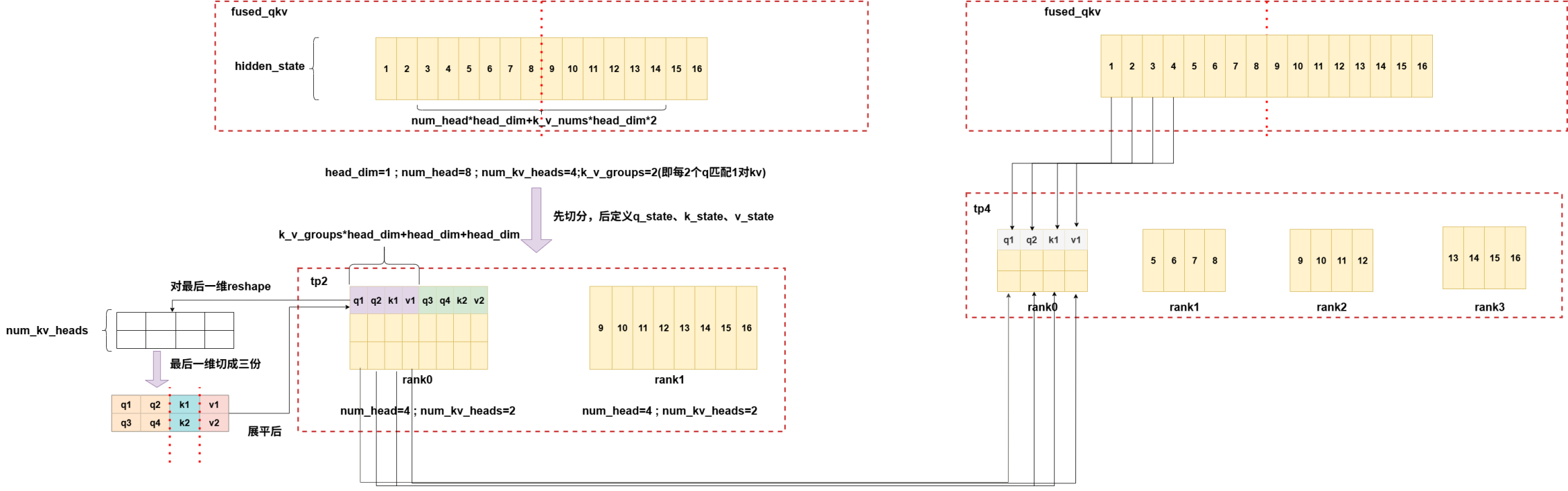
old_fused_qkv(ernie)实现逻辑图:
![]()
tp2->tp4,num_heads=k_v_nums: 此时逻辑同上,也是均分最后一维。
tp2->tp4,num_heads>k_v_nums:
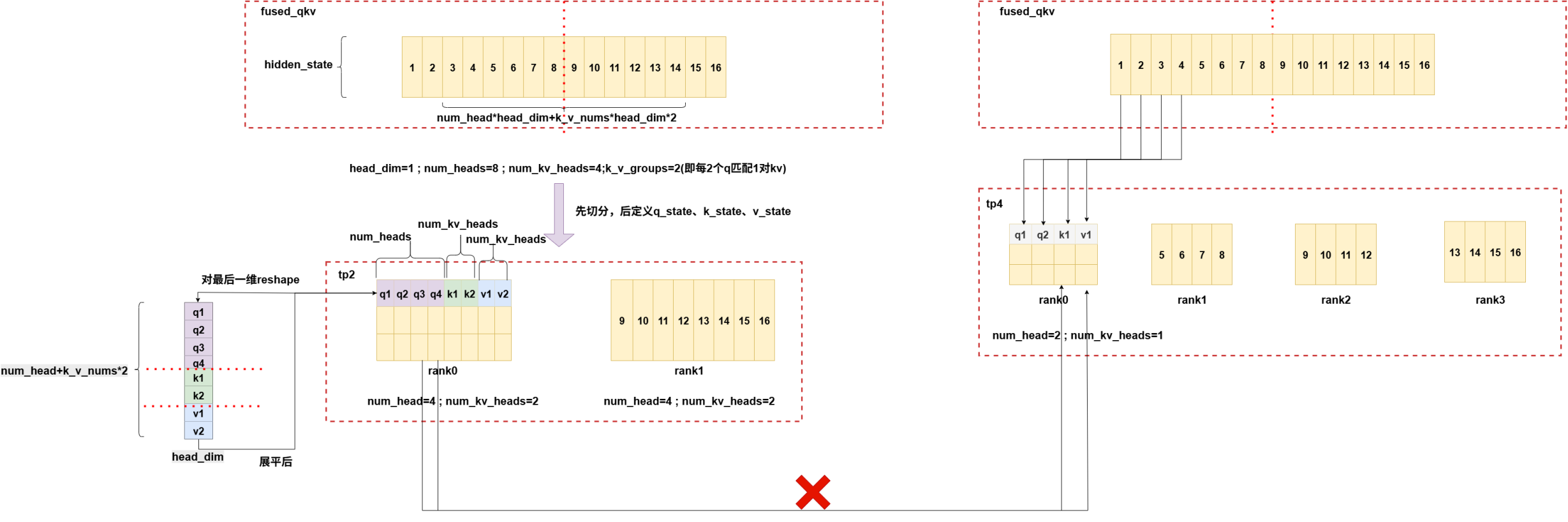
5.unified_checkpoint与flex_check_point的区别
以tp2为例,flex_check_point保存的权重,是按照参数的部分分片保存的,并没有在最后做allgather:
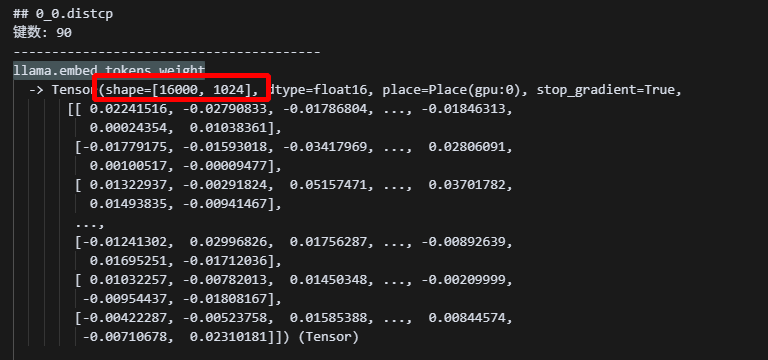
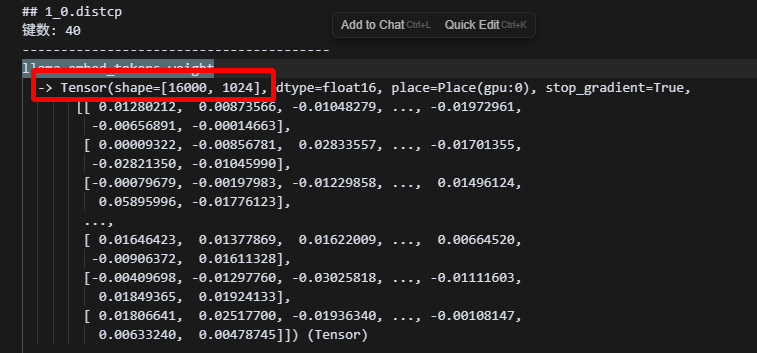
可以看到,保存下来的embed_tokens参数,仍然是按照vocab_size的大小,切成两份的形式,是一种shard的状态,注意,这里看起来像是batch被切分了,其实是因为,参数一般都以[vocab_size,batch_size]的形式排列,为了后续方便计算。
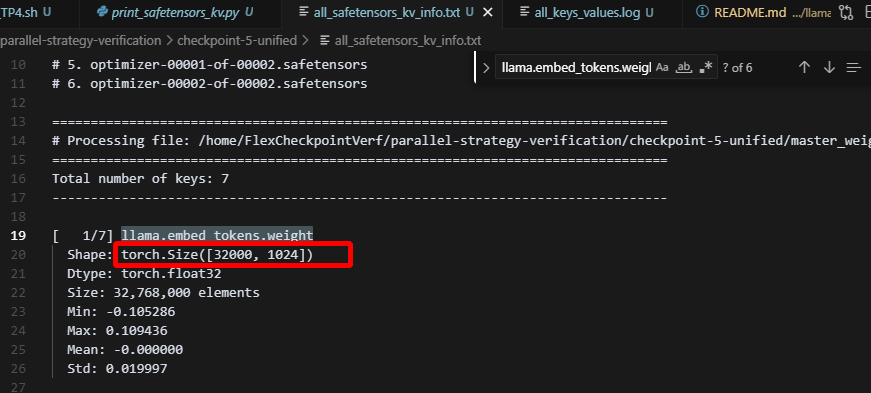
而unified_ckpt保存的权重,最后会做allgather,即所有rank上的参数都是完整参数,而保存的时候,是将所有参数划分成tp_degree份保存到多个文件中:
6.代码学习记录
1.parameters与state_dict关系
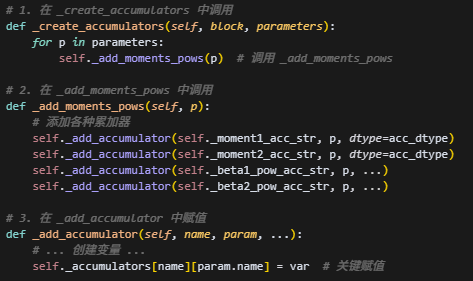
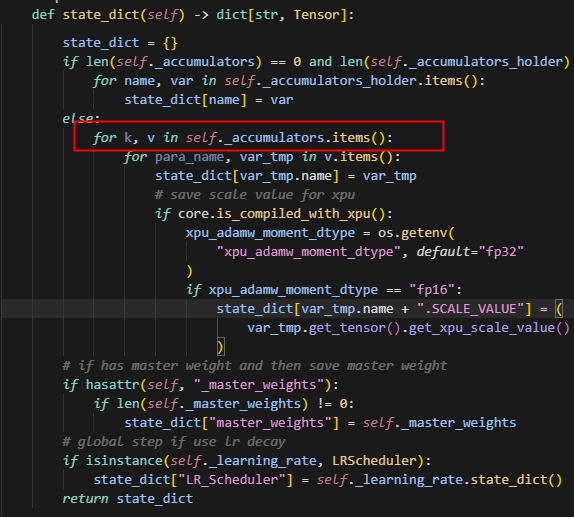
optimizer会根据param_list创建accumulators,即优化器状态参数,而state_dict会存储这些优化器状态参数,以及master_weights和LR_Scheduler。
7.合参UC测试
1.uc下optimizer的格式是
 因此需要做一个格式转换,把斜杠改成.
因此需要做一个格式转换,把斜杠改成.
2.uc跑moe模型,开ep模式下,ckpt,只会保存optimizer和master,具体在如下位置:
1.这里skip_save_model_weight被默认设置成了True,注意llm中是默认为False的
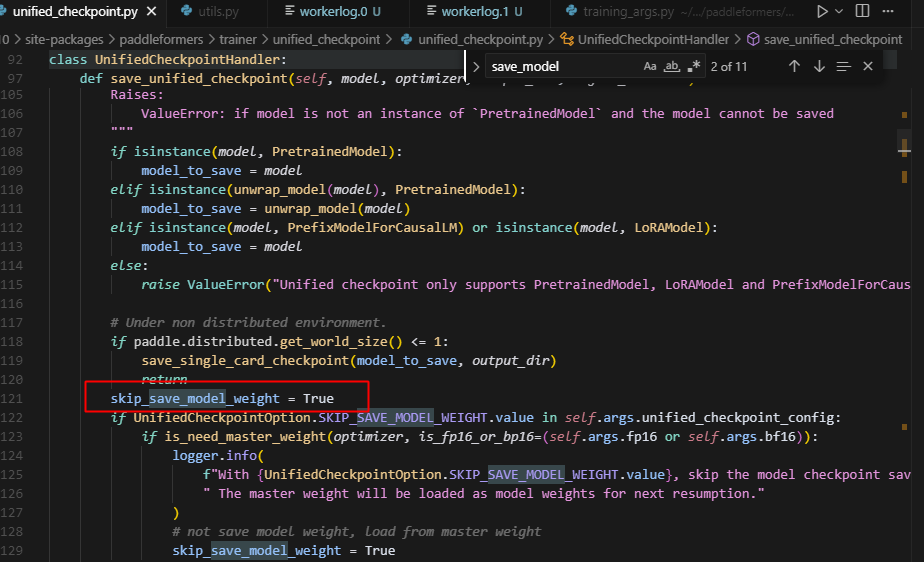
为什么这么设置呢,追溯原因如下:
1.将其设置为True,看一下报错:
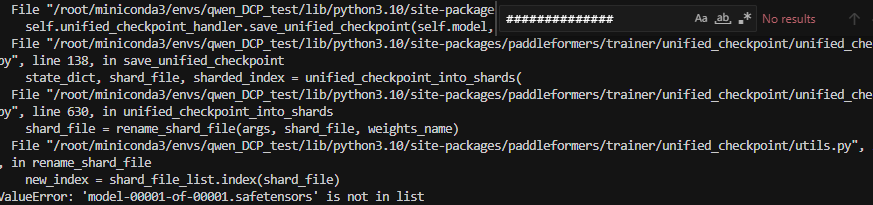
为什么会有这个报错,以下进行原因追溯:
2.首先保存ckpt的逻辑在save_checkpoint,调用save_model,此处的output_dir已经转化为了ckpt的路径
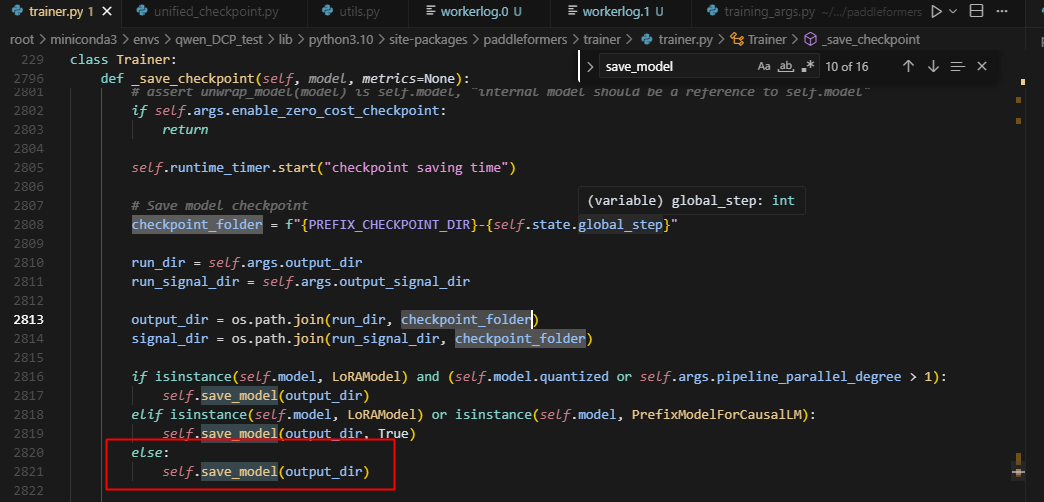
3.在save_model中,根据should_save_model_state选择是否保存model权重
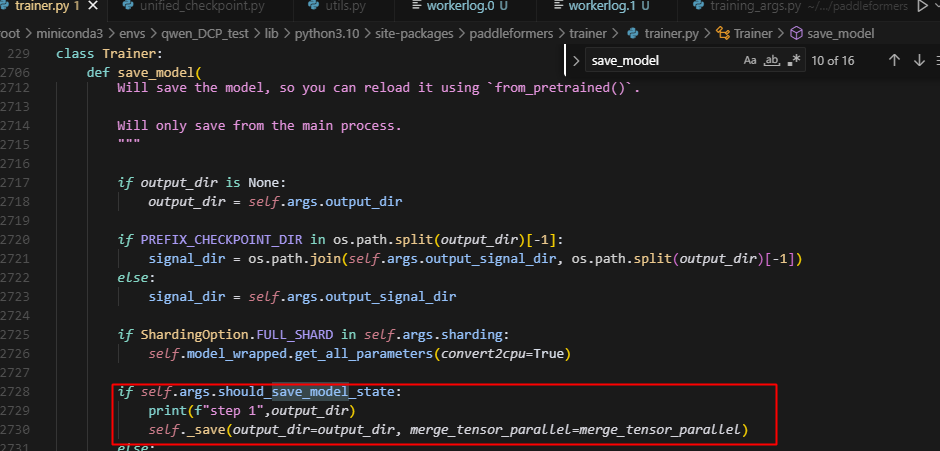
4.在_save中会调用save_unified_checkpoint函数,因为前面的默认设置,导致跳过了model参数的保存
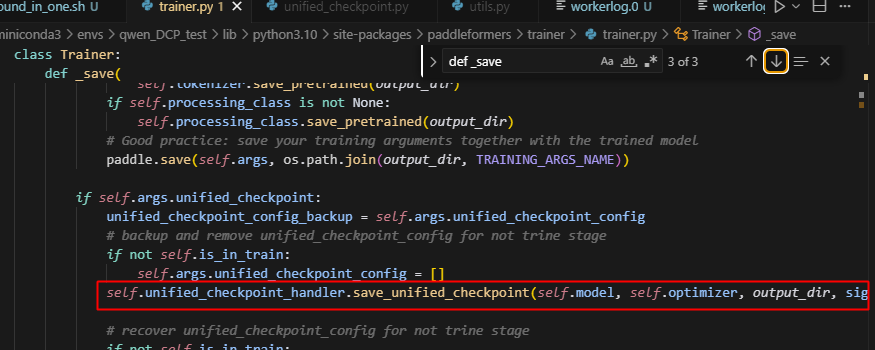
5.注意看should_save_model_state逻辑在traning_args中
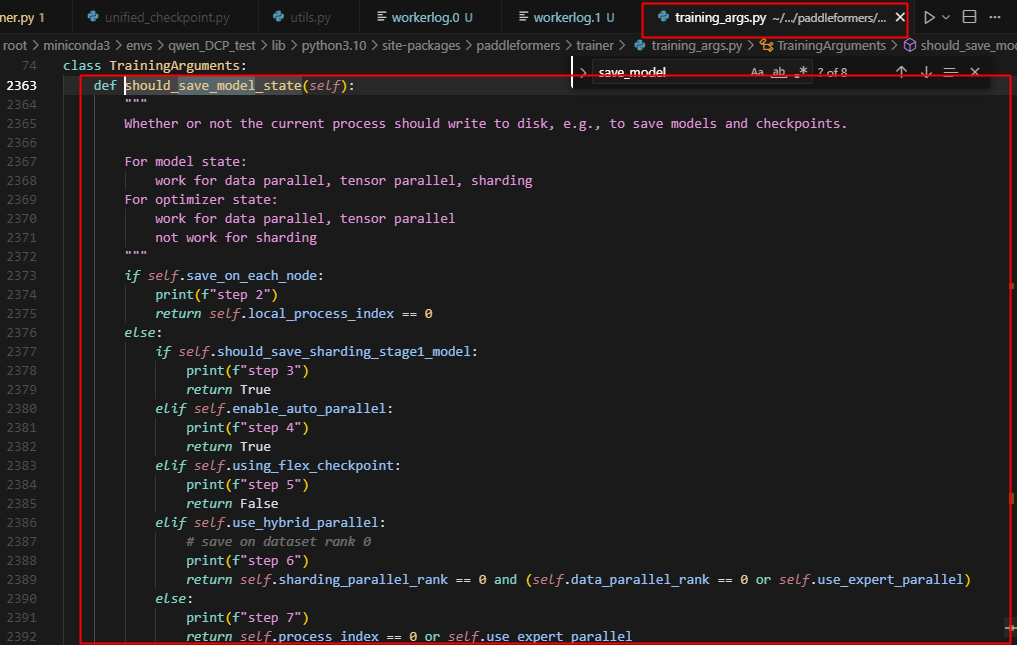
注意这里,可以看到,step6,当跑sharding2(ep2)时,可以看到,只有0卡会保存参数,而注意,开了ep之后,expert会被分到不同的rank上,如果只保存rank0上的模型参数,是有问题的,非ep下才能这么做。
6.总结报错原因
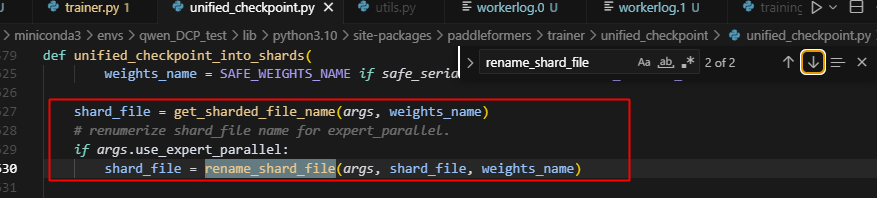
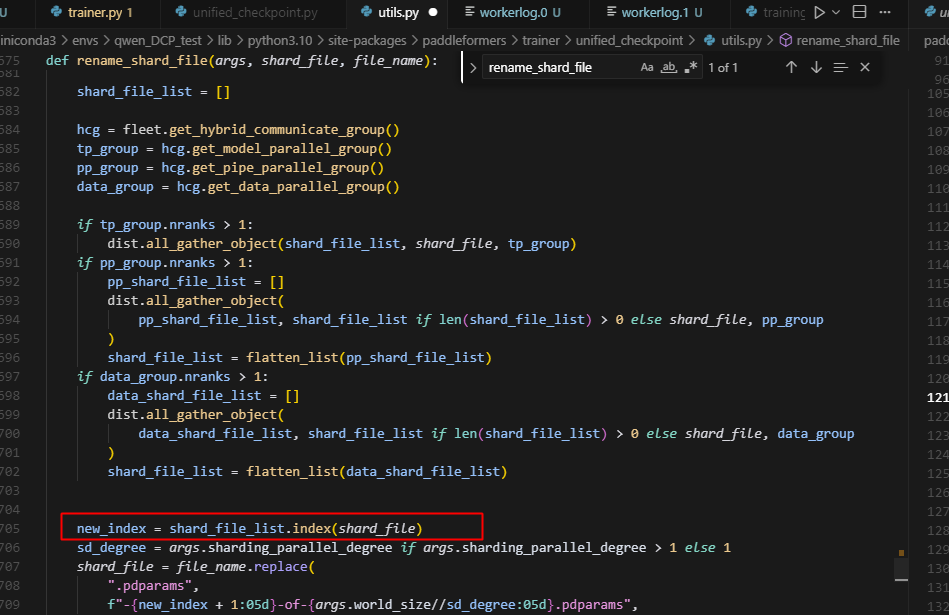
一方面,这里没有适配sharding_group的情况导致,对于sharding_ep的情况来说,此时shard_file_list是一个空列表,所以index里面访问不到现在保存的文件,另一方面,即使设置了,此时,也仅仅只有rank0会进入这条路,而rank1由于前面的should_save_model_state分析,没有进入到这条路,会导致整条路hang住,做如下修改,即可:
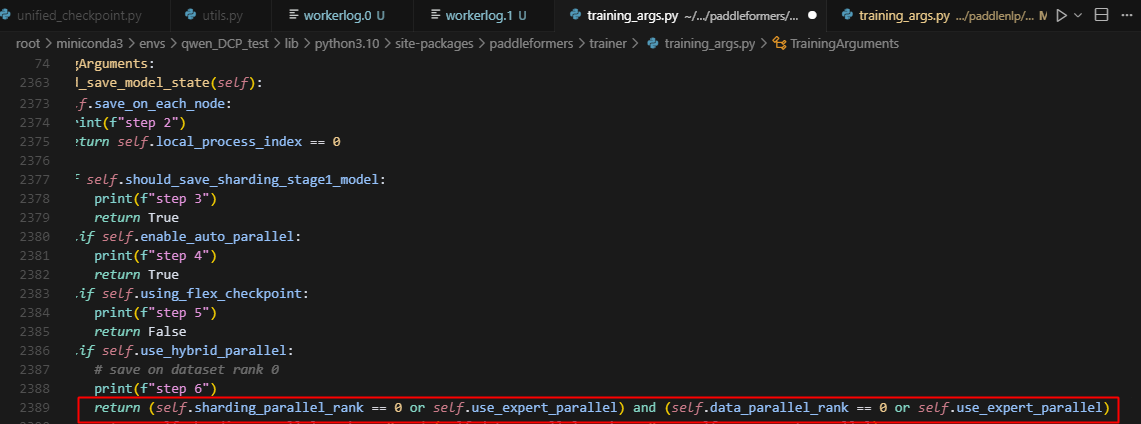
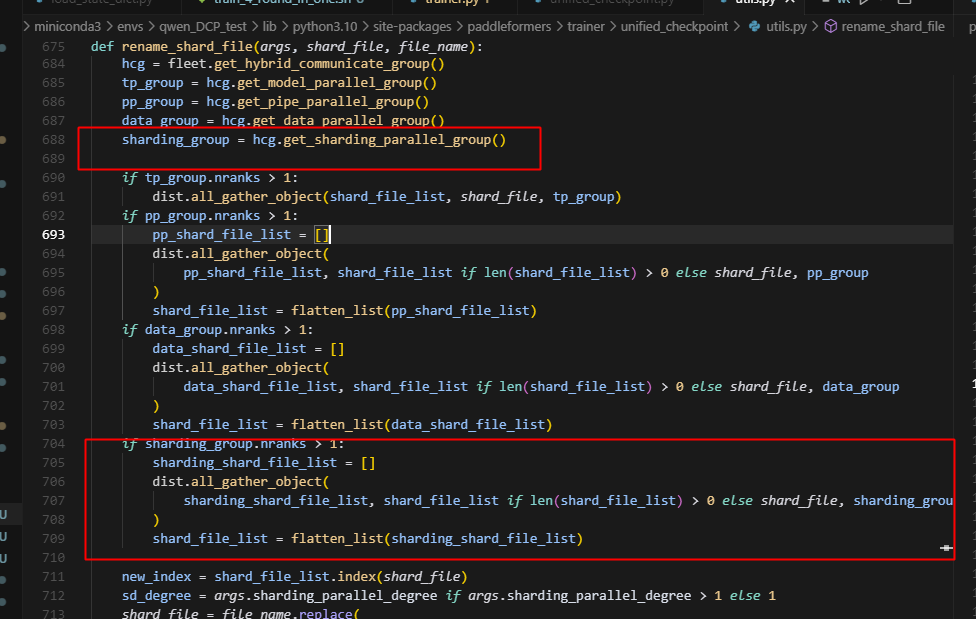
由于master_weight就能直接反应参数数据的准确性,只是和weight的精度不一致,我们直接比较master_weight就可以了。
3.uc下跑SD2EP2时,md5未对齐
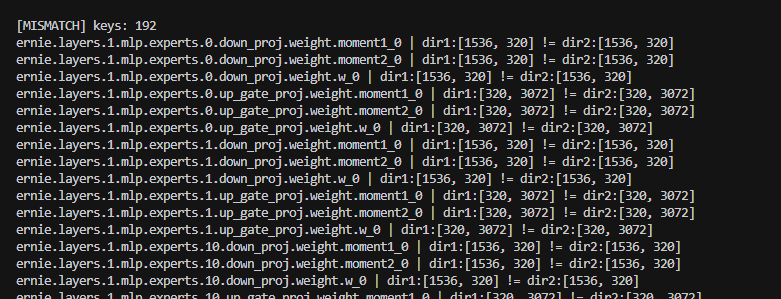
经过验证,主要原因是,fc下,会把expert,转换成key不同的情况,也就是说,比如有64个expert,分到��两个rank上的时候,编号都是0-31,而fc下,我们会把2卡的参数名修改,做数字偏移,比如0变成rank_id*(per_device_expert_nums),从而区别不同rank上的专家,而uc不会,导致对比时,uc上的expert被覆盖,比较出错,修改脚本验证后,对齐。
4.涉及TP的都会报错
追溯原因:
问题1,uc把不同rank的专家当同一个参数合并

![]()
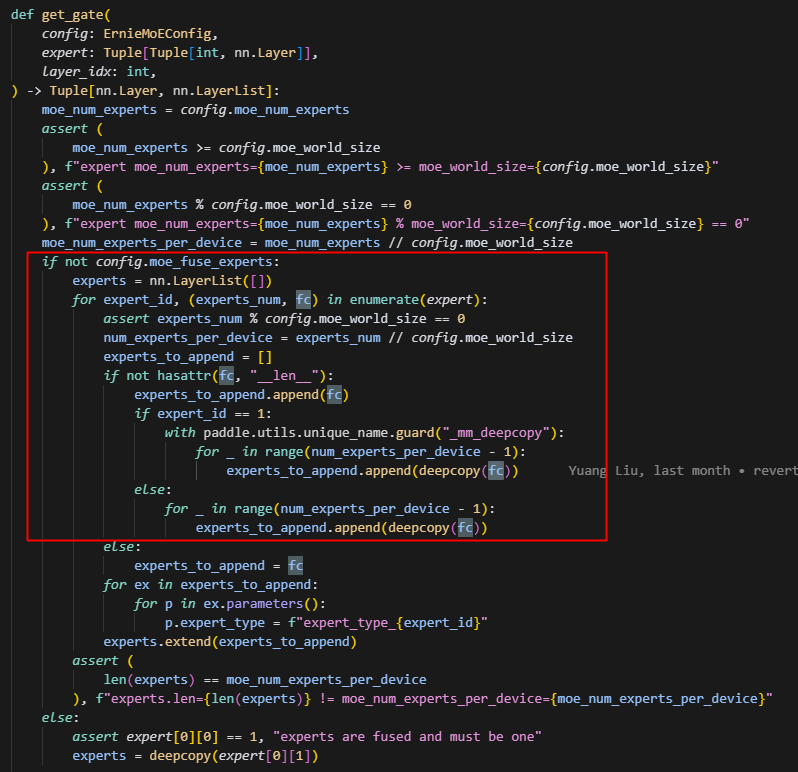
在tp下,如果moe_group是tp,则做恒等映射,是不切分专家的。只是均分到整个moe_group中,如下,fc就是ErnieMoeMLP:

但是注意:
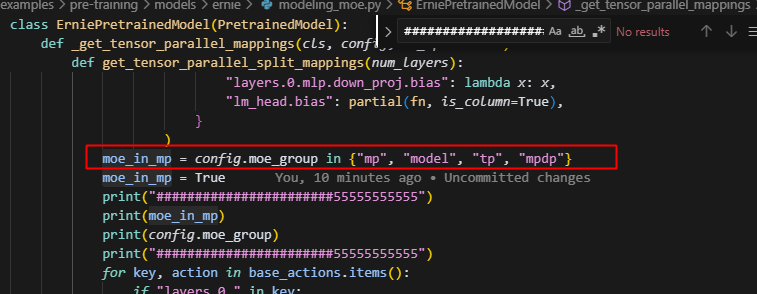
![]()

这里moe_group已经被parse_moe_group解析成了group格式,即如图,所以这里moe_in_mp始终为false,所以默认所有参数都按tp合并。所以在这里,用一个moe_group_name来提前接收moe_group字符串。
tp合并参数的逻辑如下
:
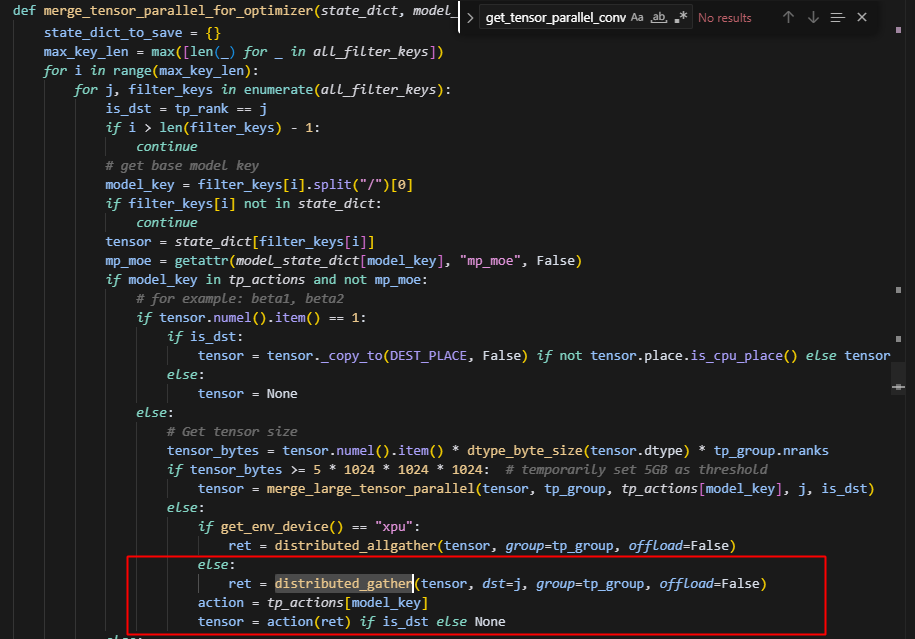
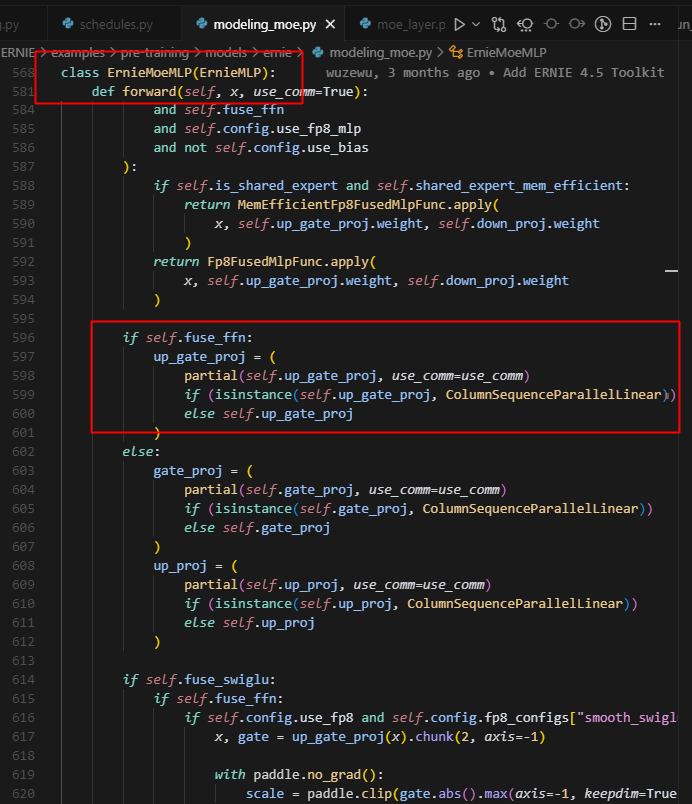
然后 action(ret) 执行,但 experts 的 action 是 partial(fn,is_column)列切,因此按列合并。
因此,两个rank上的expert会被错误合并成一个大的tensor。
问题2,未给专家参数设置mp_moe的标志,导致专家被allgather,而实际应该是直接获取本rank的,非本rank的专家参数设置为None
而,当moe_group直接设置为True的时候,action(ret) 执行,但 experts 的 action 是 lambda x: x,直接返回收集到的张量列表,所以这时候返回的tensor就是一个列表,包含rank0的expert tensor和rank1的expert tensor。仍然会导致报错。
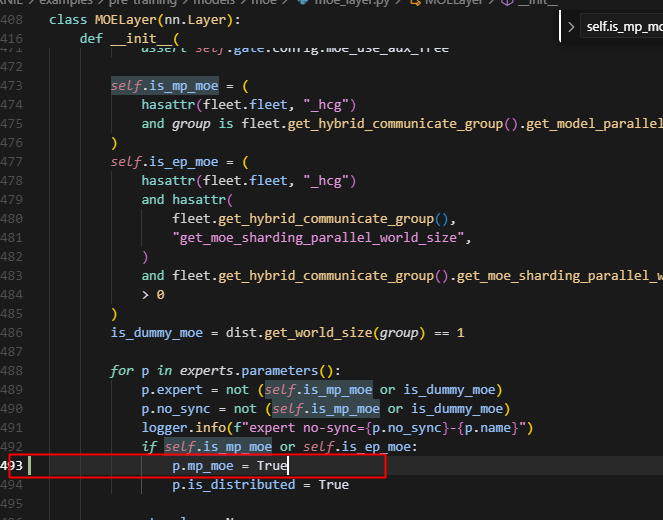
注意这里会得到一个tensor列表的主要原因是,如图处丢掉了expert的p.mp_moe的属性,导致expert无法被识别出有mp_moe属性,导致保存时,仍然保存的不是本地的expert,而是一个expert列表,即本来应该走绿色的这条分支,而现在走了红色的这条分支。
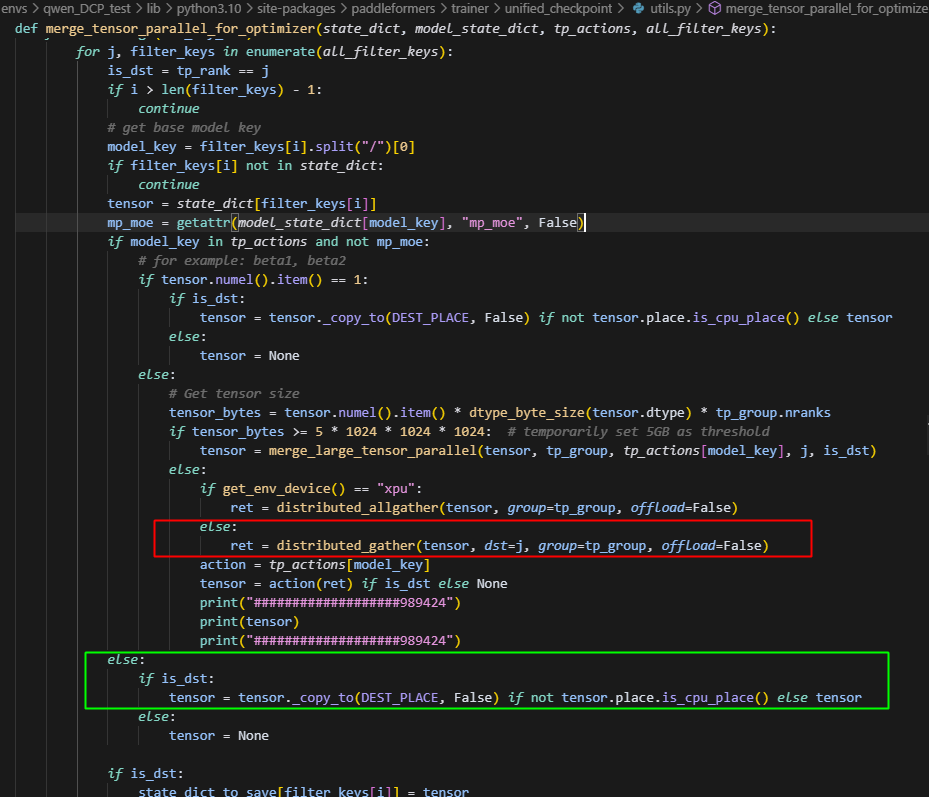
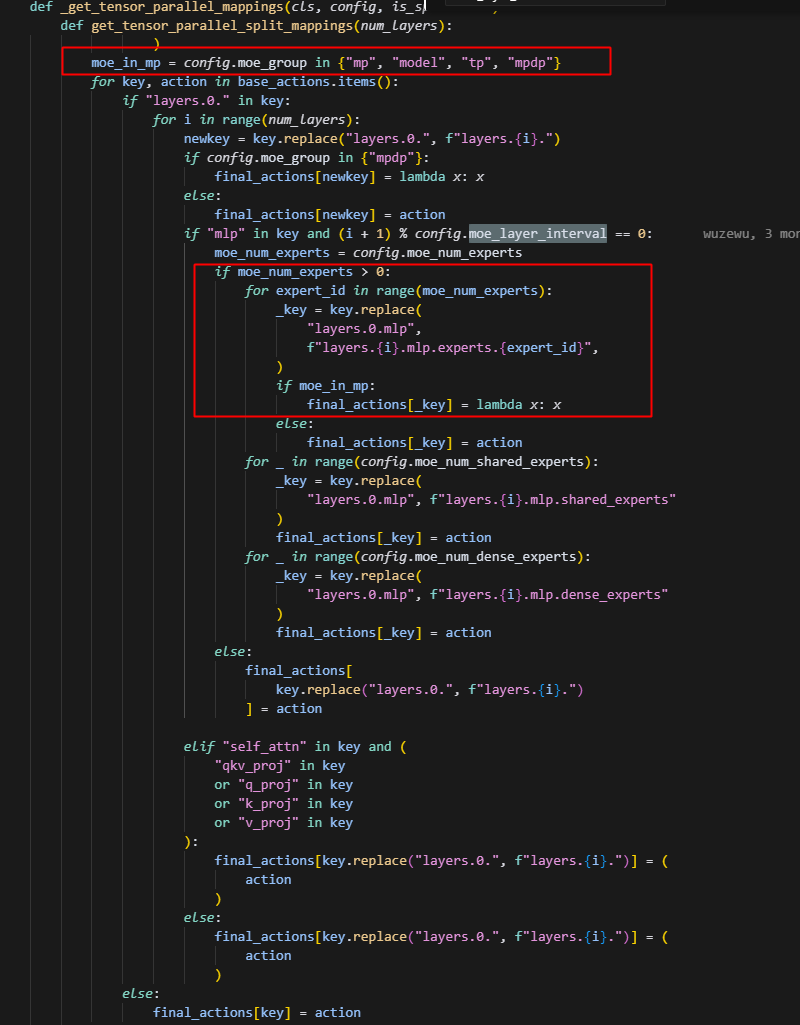
问题3,ernie_moe的_get_tensor_parallel_mappings中,未设置mtp_block层的映射,导致在save_ckpt合参时,该参数未被按tp切分维度合并

因此,需要加入如下映射,标记着其处于切分状态:
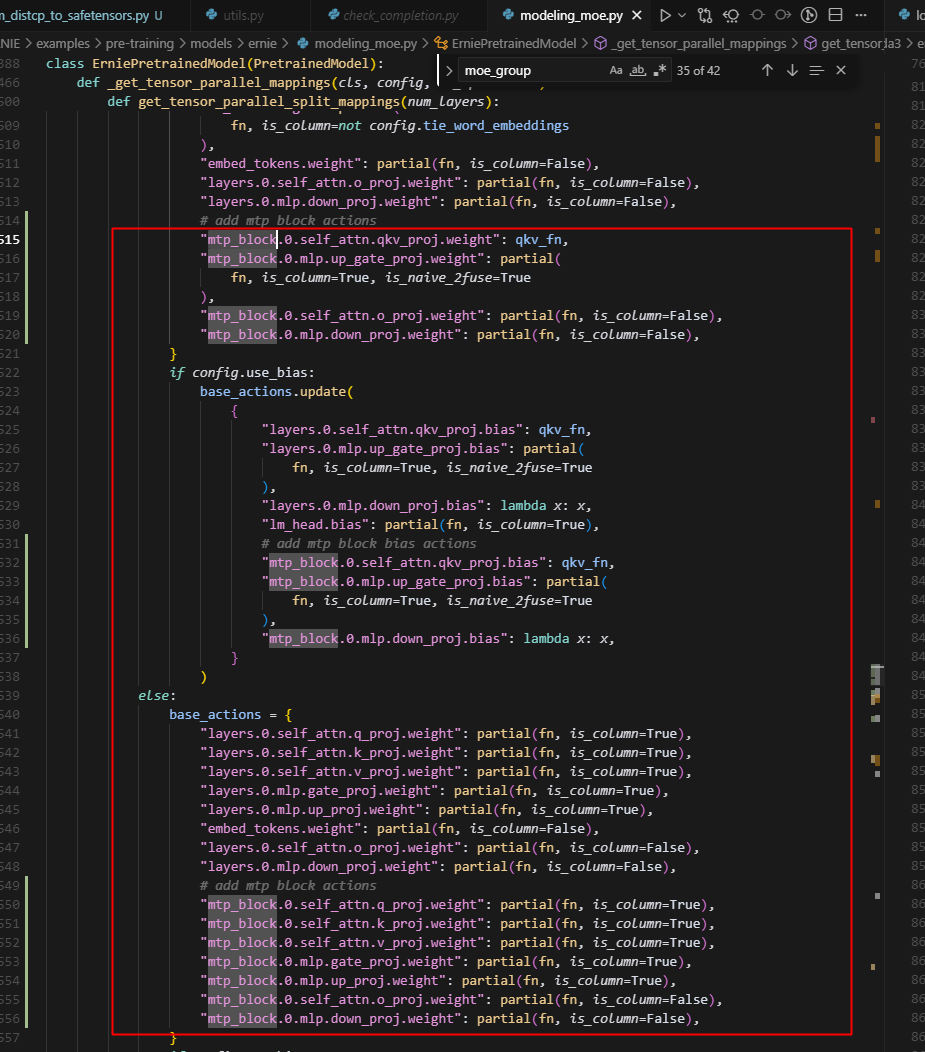
问题4,load_state_dict和_handle_aoa未考虑到多卡转单机的情况
最后,load_state_dict和_handle_aoa要适配一下多卡转单机的情况,例如加载tp4的ckpt,到单卡时,也需要用到_handle_aoa。
8.AOA测试
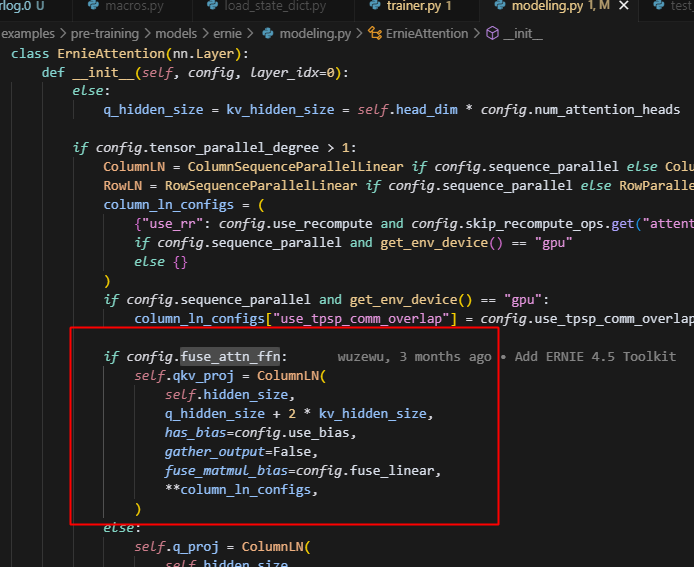
1.ernie4.5中fuse_attn_ffn同时管理qkv的fuse和ffn的fuse
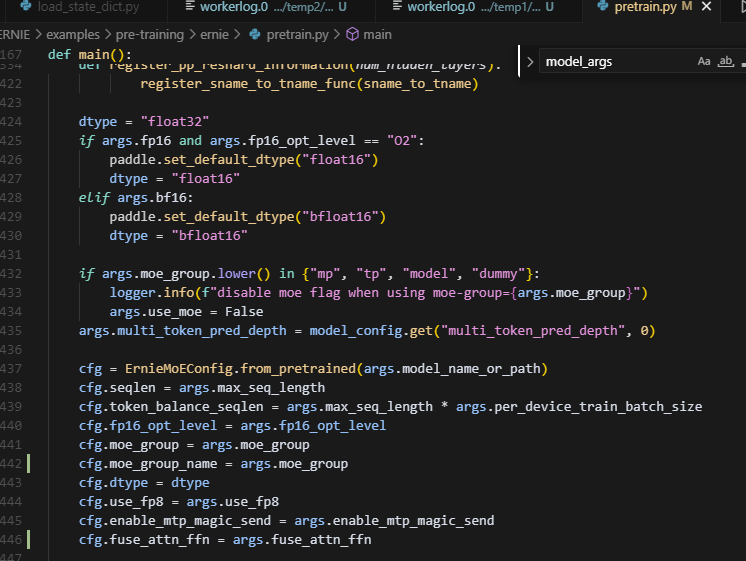
2.ernie4.5的model_args或者train_args需要在pretrain中设置传给config否则使用默认值
3.BUG1:直接拿匹配到的第一个LAYER_ID做展开,且在get_num_hidden_layers中直接用dst_state_keys匹配来计算num
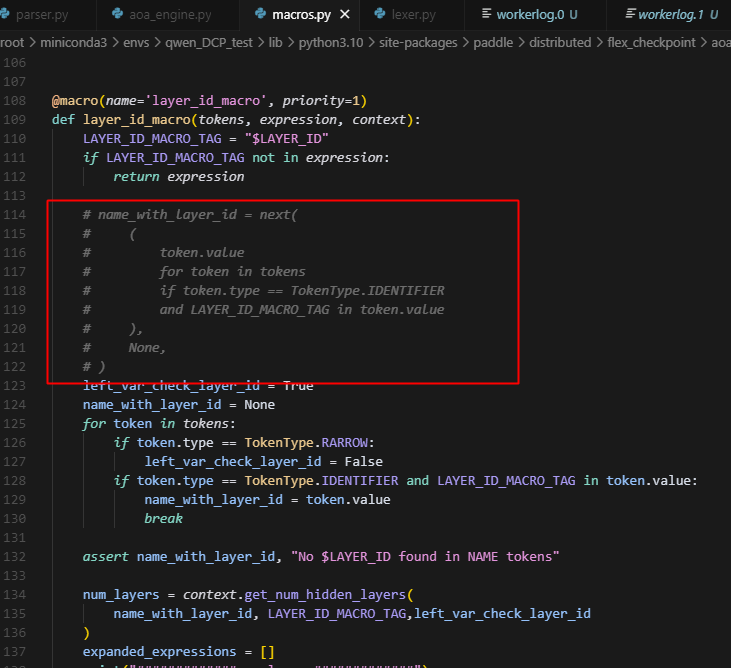
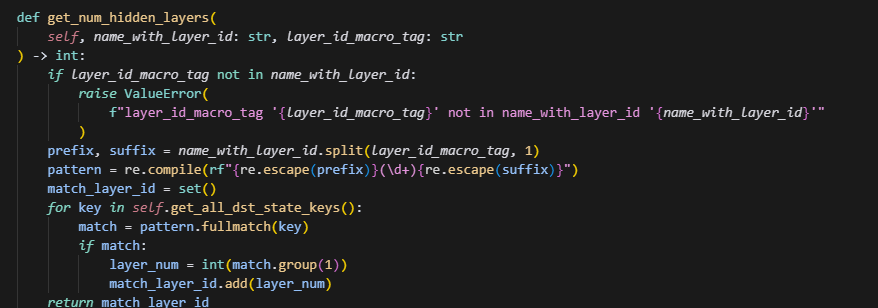
这里存在一个问题,一般箭头左边是来自src的key,而箭头右边是来自dst的key,这里的逻辑是先匹配第一个有$LAYER_ID标记的identifier,然而,在get_num_hidden_layers的时候,取的都是dst的key,那么就会发生,如果箭头左右两边的key并不一样,例如qkv->q,k,v时,就会出现key匹配不上的现象,从而返回了一个空的set,导致整个expanded_expressions被返回了一个空列表。
4.专家并行下,需要给expert_id也配个marco,主要是为了拆解成多个fuse_ffn操作

如果直接用*展开,会变成多->多 fuse_ffn操作,不匹配任何原语,需要拆解。
5.在rename的场景下,缺失result
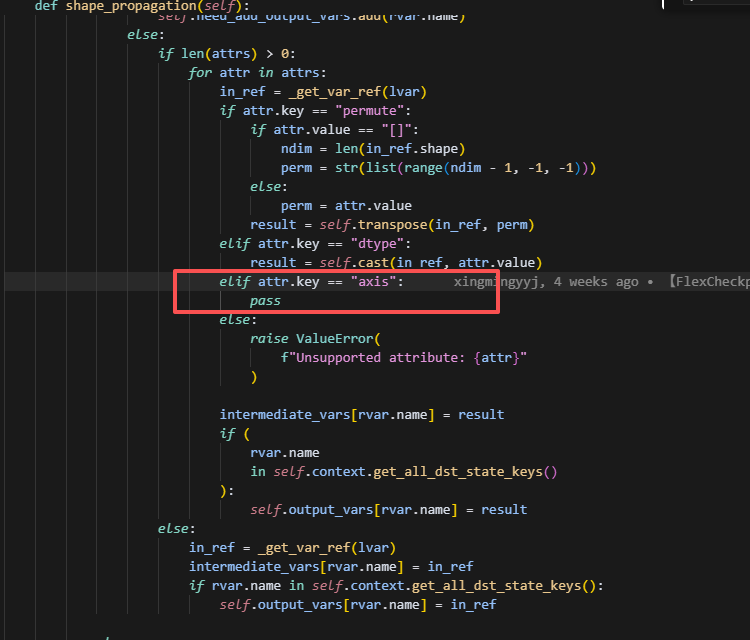
在这里应该给result赋值为result = in_ref,即直接获取lvar的内容,并用rvar的name命名,即实现rename。
6.init_optimizer的逻辑存在问题
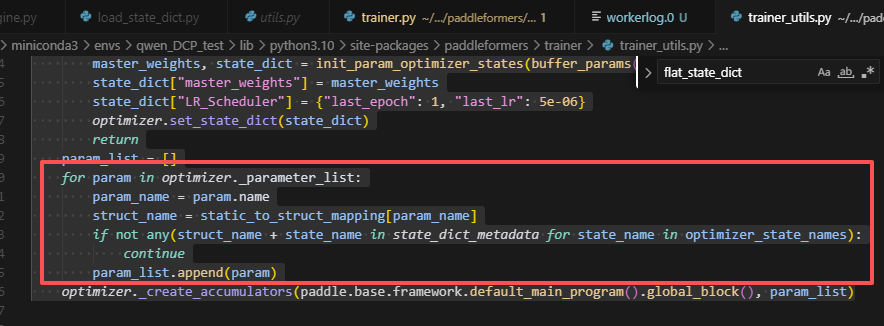
当前的逻辑,会读取metadata,然后根据其中存在的优化器状态来过滤,判断是否要创建当前optimizer内的参数的优化器状态;然而存在一个问题,例如,当fuse_qkv->q,k,v这种情况时,原来的metadata文件,是没有q,k,v的优化器状态的,但是却需要做转换,所以也要初始化q,k,v的优化器状态,因此,不能在此处做过滤,而是在后续做过滤,修改方法如下:
首先在paddlenlp中,必须先根据optimizer中的key,为所有的参数创建优化器状态。 其次,如下位置:
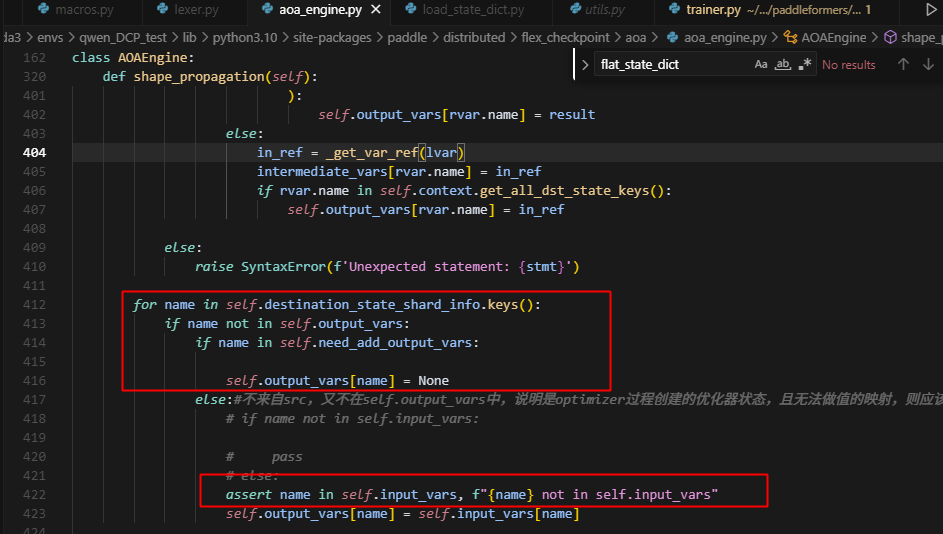
当判断这个key在dst_shard_info中,而不在output_vars中,首先说明aoa没有对该参数做配置,其次又不在add_vars中,也说明并没有将其设置为添加的变量,最后它也不在input_vars中,那么就说明,这个key是在init_optimizer时创建的,是多余的,无需处理的,因此需要丢掉。所以新增一个过滤的set,保存无需处理的optimizer_key,并在handle_aoa中调用。如下:



后续注意,如果要修改,要注意添加一个no_need_master_weights
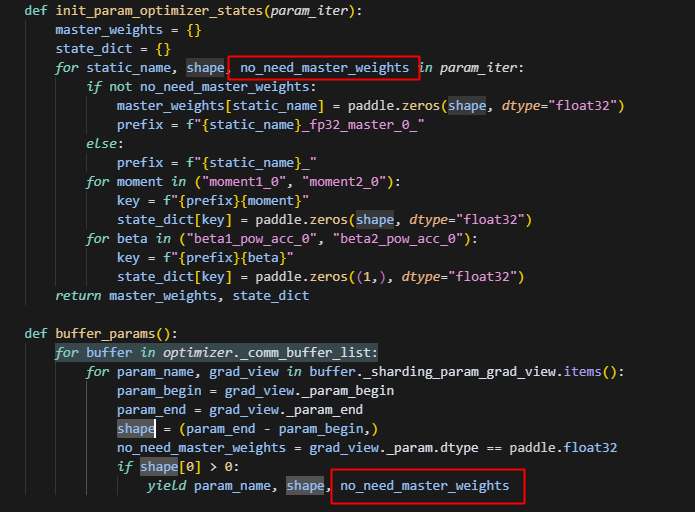
主要是为了确保有一些不需要master_weights的参数不被初始化w_0。
7.当同一个键值想转多个键值时,会被覆盖
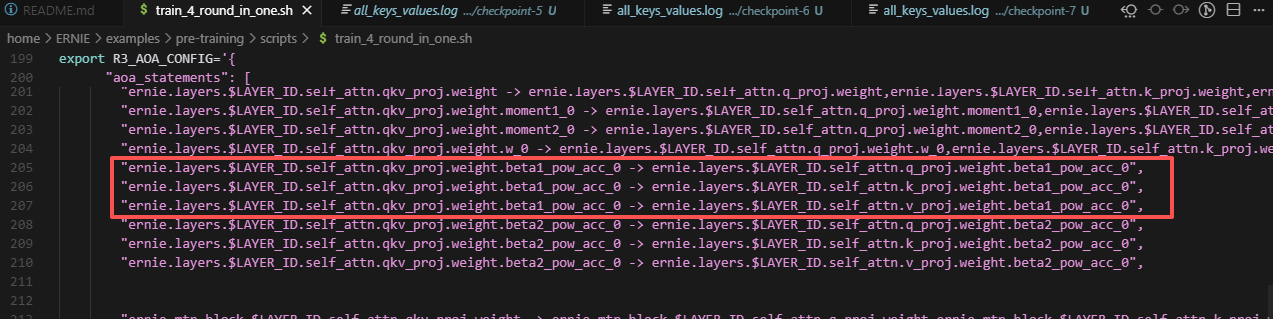
例如,动量大小是1,因此在qkv->q,k,v的场景下,应该直接把qkv对应的动量直接分别赋值给q,k,v对应的动量,三者动量完全相同。
但是,现在的代码并不支持,原因是,如下位置:
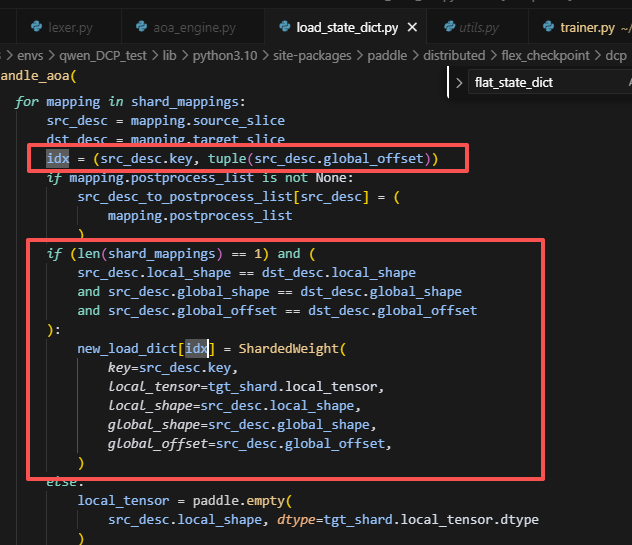
当从同一个src_var赋值时,这里的idx会是相同的,此时,若后续还有同样需要这个src_var赋值的,则会覆盖掉前面的,例如q,k,v最后保留的local_tensor就是v,所以只有v被正确赋值了。
8.注意ffn的聚合和拆分
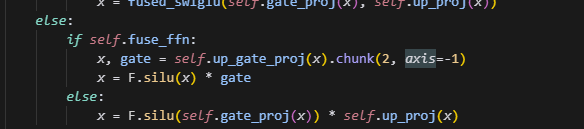
合并时,在做计算时,将up_gate拆分成两份,一份对应x,一份对应gate,而这两个分别对应非fused时的,gate_proj(x)和up_proj(x),因此注意不要弄反了。
9.star_macro在匹配时需要严格匹配,否则匹配某个weight时,会把优化器状态也匹配进去

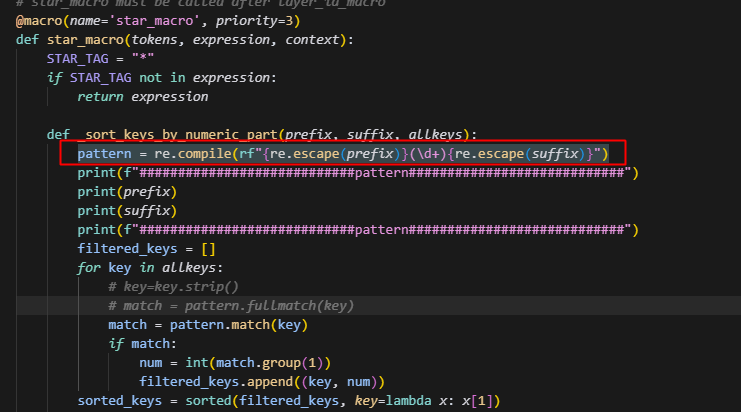

fullmatch即可
9.AOAEngine学习记录
1.AOAShardInfoContext
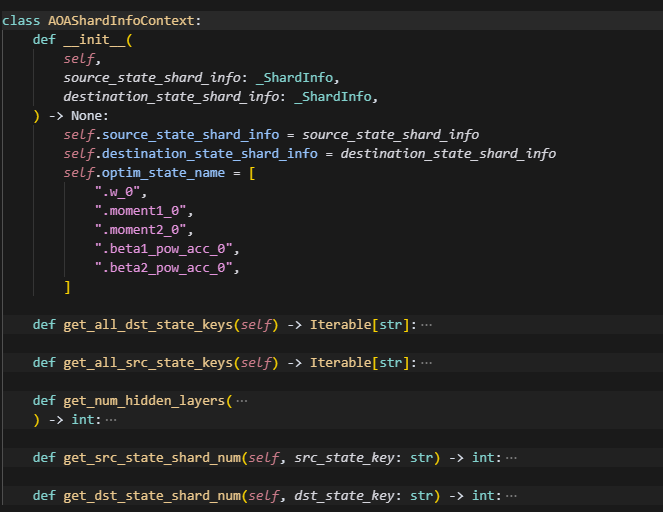
这个主要用于记录上下文信息,保留一些信息,给后续操作可调用。
source_state_shard_info和destination_state_shard_info分别表示需要load下来的ckpt对应策略的参数分片信息,和当前正在执行的策略的参数分片信息,格式为_ShardInfo = dict[str, list[ShardedWeightDesc]],即包含,同一个key,再不同rank上的参数分片状态(包括local_shape,global_shape,global_offset),如果是类似dp这样的,同一个key只会在单个distcp文件中保存,因此只有一个参数分片状态。
get_all_dst_state_keys与get_all_src_state_keys则是辅助函数获取其中所有的key,get_num_hidden_layers通过aoa_config中是否配置了$LAYER_ID,来正则匹配dst中所有key中的layer_id,例如下:
"ernie.layers.$LAYER_ID.self_attn.qkv_proj.weight -> ernie.layers.$LAYER_ID.self_attn.qkv_proj.weight, fused_qkv_old, num_heads=20, num_key_value_groups=5"
会以$LAYER_ID为分隔符,分成两份,然后中间以\d匹配,从而匹配到layer_id,遍历所有key,得到的做大ID+1,则为num_hidden_layer的层数。
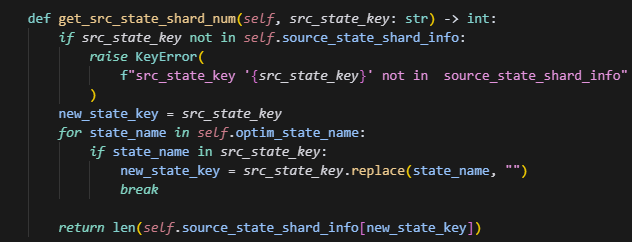
get_src_state_shard_num和get_dst_state_shard_num这两个主要是查看当前key对应参数的分片数,即tp数。
为什么要把optmizer的key也都转换成model的key来算呢,原因是,当做sharding的时候,opt的参数分片数=tp_nums*sharding_nums,直接求就有问题了。
2.Lexer(词法分析器)
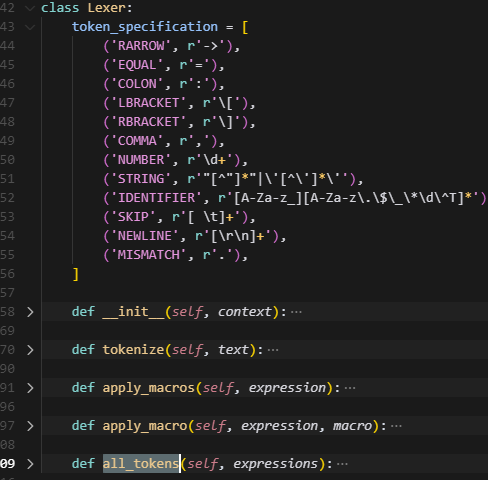
核心目标:为 AoA 表达式做词法分析(Lexing),并在词法分析前先应用已注册��的宏展开,最终生成供解析器使用的 token 序列。
首先传入的参数expressions是aoa_conifg["aoa_statements"],这是一个字符串列表,形状如下:
--aoa_config '{
"aoa_statements": [
"llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight -> llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight, fused_ffn",
"llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight.moment1_0 -> llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight.moment1_0, fused_ffn",
"llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight.moment2_0 -> llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight.moment2_0, fused_ffn",
"llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight.w_0 -> llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight.w_0, fused_ffn"
]
}' \
每一个expression会使用apply_macros,即对每个expression,遍历使用所有的已经注册好的macro。
在进入macro之前,会使用tokenize方法将expression解析成多个token,按照token_specification中的正则项进行匹配,name作为key,匹配到的实际内容作为value,比如上述的aoa_config的第一条,首先会根据identifier获取到第一个token:llama.layers.$LAYER_ID.mlp.gate_up_fused_proj.weight,遇到空格会skip,然后根据rarrow匹配到->,紧接着再根据identifier获取到下一个token,知道最终结束,而每个text都会判断一下后面有没有\n,没有就补充,从而得到NEWLINE,标志着一条text匹配结束(必须注意,这里加\n,就可以在后续调用parser的时候,读取到这个换行符,结束当�前这一行statement的解析)。
被所有macro处理后,会得到一个results列表,列表里面也都是expression样子的表达式,最终Lexer会把result_expression再次调用tokenized解析成token返回,给到parser里面做处理。
3.Parser(语法分析器)
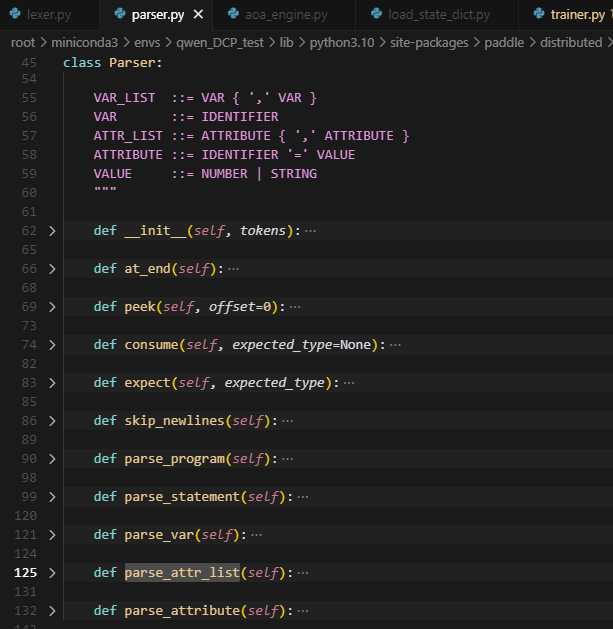
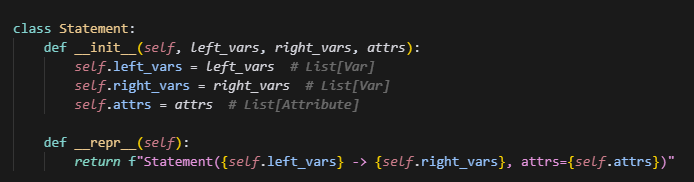
这个Parser解析器,主要是对macros处理后的statement(由macros处理后,新生成的aoa表示语句),并且被Lexer处理成一个token列表,针对这个token列表做分析,每个statement会被分成多个token,根据token_type,最终得到left_var,right_var,attribute。
主要调用函数就是parse_statement,根据IDENTIFIER(标识符)、COMMA(逗号)、RARROW(箭头)、EQUAL(等号)、NEWLINE(\n)、来区分,当前的token是属于left_var,right_var,attribute的哪一个。最终会返回一个List[Statement],包含每一个statement解析获得的Statement。
4.Macros
5.AOAEngine
所有模型结构相关的参数转换,都可以使⽤rename、merge、split、transpose、cast、remove和add这7种原语组合出来。
下面按 7 种原语给出判定条件与规范格式(AOA 一条语句的通用形态是:左变量列表 -> 右变量列表[, 属性列表]):
- 重命名 rename
- 条件:左 1 个,右 1 个,且无属性
- 格式:`A -> B`
- 合并 merge(concat)
- 条件:左 多个,右 1 个,且属性仅有 `axis`,缺省axis=0
- 格式:`A, B, C -> OUT, axis=1`
- 切分 split(split)
- 条件:左 1 个,右 多个,且属性仅有 `axis`,缺省axis=0
- 格式:`IN -> A, B, C, axis=1`
- 置换 transpose(permute)
- 条件:左 1 个,右 1 个,属性含 `permute`
- 格式:`A -> B, permute=[2,0,1]`
- 特例:`permute=[]` 表示维度反转(代码里会按 ndim-1..0 生成,维度完全颠倒)
- 类型转换 cast
- 条件:左 1 个,右 1 个,属性含 `dtype`
- 格式:`A -> B, dtype='float16'`(字符串字面量外层引号会被去掉)
- 移除 remove
- 条件:左 1 个,右为下划线 `_`
- 格式:`A -> _`
- 新增 add(占位声明输出名)
- 条件:左为下划线 `_`,右 1 个
- 格式:`_ -> B`
补充约束与细节:
- split/merge 必须且只能带一个 `axis` 属性,否则报错。
- 单输入单输出可同时带多个属性,但仅支持 `permute` 与 `dtype`(`axis` 会被忽略)。
- 属性间用逗号分隔;属性解析不跨行。
- 变量名 `_` 仅在 add/remove 中有特殊含义。
1.TensorDesc
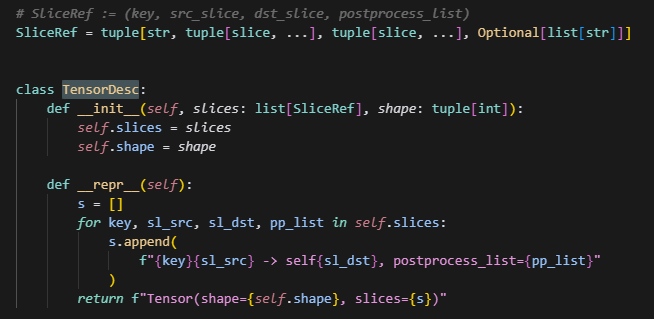
-
src_key: 源权重名(字符串)
-
sl_src: 源全局张量上的切片 tuple(每个维度一个 slice)
-
sl_dst: 目标张量上的切片 tuple(对应 sl_src 区间映射到目标的区间)
-
pp_list: 后处理列表(如转置 permute 列表字符串、dtype 标记),用于反向或正向应用
什么时候,slices会是一个列表呢?
比如,当要合并某个参数时,可能是将这个参数的多条slice合并成一个tensor,因此是一个列表。
2.find_shard_sources
s0 = ShardedWeightDesc(
key="s0",
local_shape=(2, 2),
global_shape=(2, 2),
global_offset=(0, 0),
)
s1 = ShardedWeightDesc(
key="s1",
local_shape=(2, 2),
global_shape=(2, 2),
global_offset=(0, 0),
)
d0 = ShardedWeightDesc(
key="d0",
local_shape=(4, 1),
global_shape=(4, 1),
global_offset=(0, 0),
)
d1 = ShardedWeightDesc(
key="d1",
local_shape=(4, 1),
global_shape=(4, 1),
global_offset=(0, 0),
)
self.source_state_shard_info = {
"s0": [s0],
"s1": [s1],
}
self.destination_state_shard_info = {
"d0": [d0],
"d1": [d1],
}
self.aoa_statements = [
"s0, s1 -> s, axis = 1 \n",
"s -> s, dtype = 'float64'\n",
"s^T -> d\n",
"d -> d0, d1, axis = 1",
]
###################################################################################
query = ShardedWeightDesc(
key="d1",
local_shape=(4, 1),
global_shape=(4, 1),
global_offset=(0, 0),
)
# d1[0:2, :] <--- s0[1, :]^T
src_sharded_weight_desc0 = ShardedWeightDesc(
key="s0",
local_shape=(1, 2),
global_shape=(2, 2),
global_offset=(1, 0),
)
dst_sharded_weight_desc0 = ShardedWeightDesc(
key="d1",
local_shape=(2, 1),
global_shape=(4, 1),
global_offset=(0, 0),
)
# d1[2:4, :] <--- s1[1, :]^T
src_sharded_weight_desc1 = ShardedWeightDesc(
key="s1",
local_shape=(1, 2),
global_shape=(2, 2),
global_offset=(1, 0),
)
dst_sharded_weight_desc1 = ShardedWeightDesc(
key="d1",
local_shape=(2, 1),
global_shape=(4, 1),
global_offset=(2, 0),
)
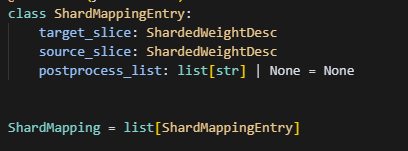
shard_mapping_entry0 = ShardMappingEntry(
target_slice=dst_sharded_weight_desc0,
source_slice=src_sharded_weight_desc0,
postprocess_list=["float64", "[1, 0]"],
)
shard_mapping_entry1 = ShardMappingEntry(
target_slice=dst_sharded_weight_desc1,
source_slice=src_sharded_weight_desc1,
postprocess_list=["float64", "[1, 0]"],
)
answer = [shard_mapping_entry0, shard_mapping_entry1]
self.queries.append(query)
self.answers.append(answer)
idx=0;
query = self.queries[idx]
answer = self.answers[idx]
result = self.aoa_engine.find_shard_sources(query)
self.assertEqual(result, answer)
如上举个例子,find_shard_sources,得到的是,一个ShardMapping,ShardMapping = list[ShardMappingEntry],ShardMappingEntry保存了一个source_slice切片的对应位置的数据,映射到target_slice切片的什么位置,以及映射过去要做什么操作,即postprocess_list,因此ShardMappingEntry包含三个参数。比如上面这个例子,上面展示了一个,从两个2*2的tensor,按axis=1维度拼接后,转置成4*2的矩阵,接着再转换dtype,同时按照axis=1切分,得到d1,d2。而此时,find_shard_sources(query),即将d1的切片信息输入,就可以获取到这个d1的数据,是由source的哪些切片数据获取的,可以用下图展示:
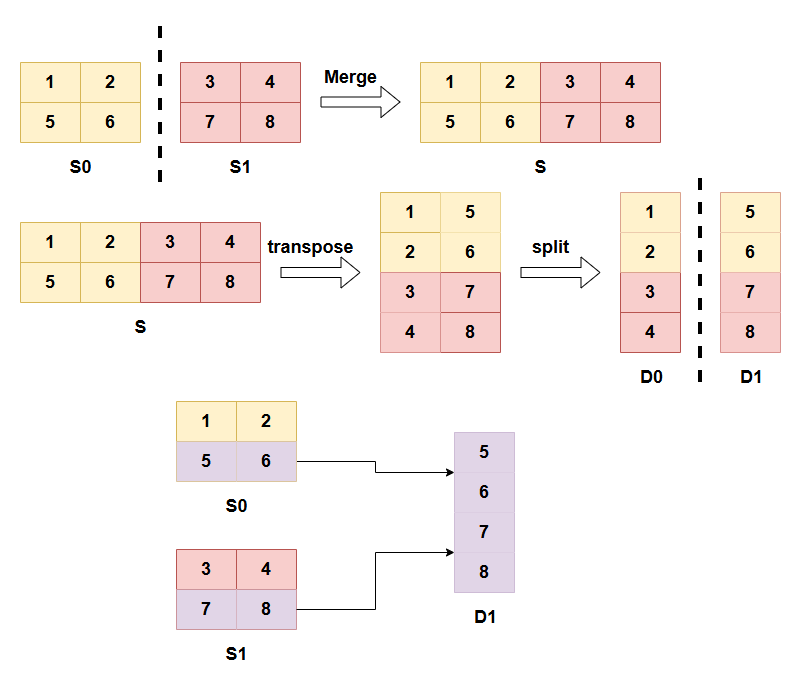
可以看到,find_shard_sources(D1)将得到两个ShardMappingEntry,一个是S0的第一行切片对应D1的前两行,另一个是S1的第二行切片对应D1的后两行,并且要做一个转置操作。